Landskabet af AI-chatbots udvikler sig med en hidtil uset hastighed. Så snart en organisation afslører sin seneste model, er konkurrenterne hurtige til at følge trop og stræber efter at overgå hinanden. På trods af at OpenAI’s ChatGPT nyder et tidligt forspring på denne konkurrencemæssige arena, har rivaler som Gemini hurtigt vundet indpas og sofistikering.
Blandt de nuværende frontløbere inden for AI-chatbot-udvikling er ChatGPT- og Gemini-modellerne. Inden for denne sammenligning fokuserer vi specifikt på ChatGPTs 4o-model og Geminis 1.5 Pro, som begge er premium-tilbud, der er skræddersyet til forskellige opgaver.
At vælge mellem disse førende modeller er afgørende for effektivt at imødekomme dine unikke krav. Derfor gennemførte vi en række strenge præstationstests for at se, hvilken model der udmærker sig ved en lang række opgaver. Lad os dykke ned i analysen!
1. Matematikprøve
Vores første udfordring involverer at tackle en kompleks matematisk gåde designet til at måle hver models ræsonnementevner:
Hurtig: If 1=3, 2=3, 3=5, 4=4, and 5=4, what is 6?
Nøglen til at løse denne gåde ligger i at tælle bogstaverne i talnavnene: en har tre bogstaver, tre har fem, og derfor har seks tre bogstaver. Begge modeller formåede at nå frem til den rigtige løsning, men deres forklaringer varierede:
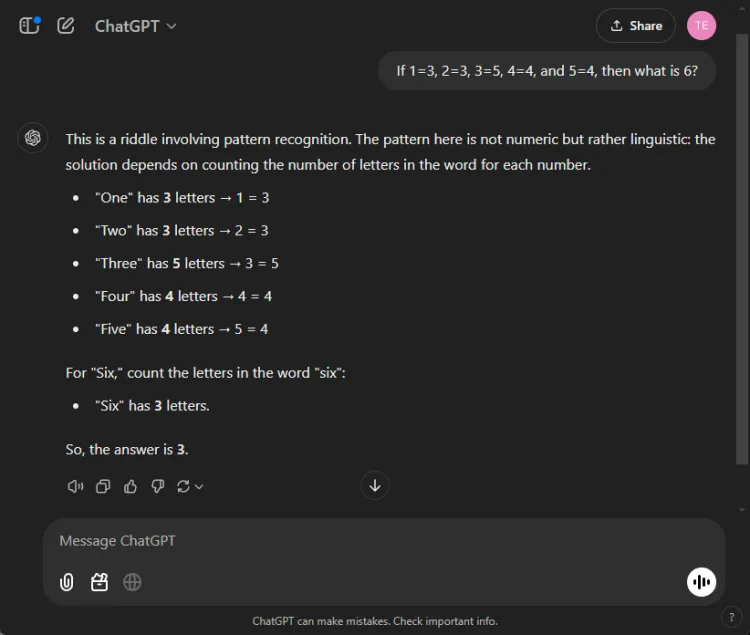
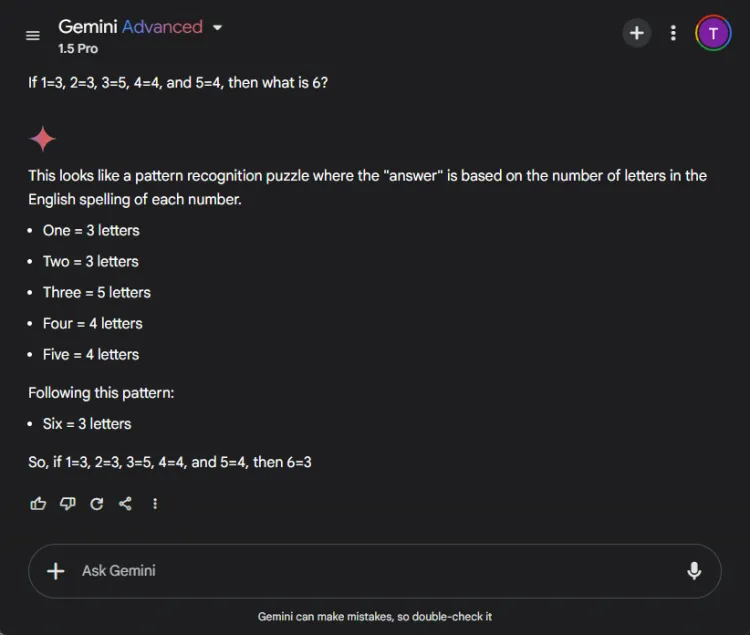
Selvom begge svar var nøjagtige, gav ChatGPT en lidt mere nuanceret forklaring, idet han bemærkede, at denne øvelse er afhængig af sproglig snarere end numerisk forståelse. Denne nuance er dog subjektiv og formindsker ikke Geminis korrekthed.
Vinder: slips
2. Opsummeringstest
Dette segment vurderede hver models evne til at kondensere en lang 27-siders forskningsartikel til et kortfattet resumé på færre end 100 ord. Fokus var på, hvilket indhold hver model inkluderede eller udelod i deres resuméer.
Sådan varierede output mellem ChatGPT 4o og Gemini 1.5 Pro:
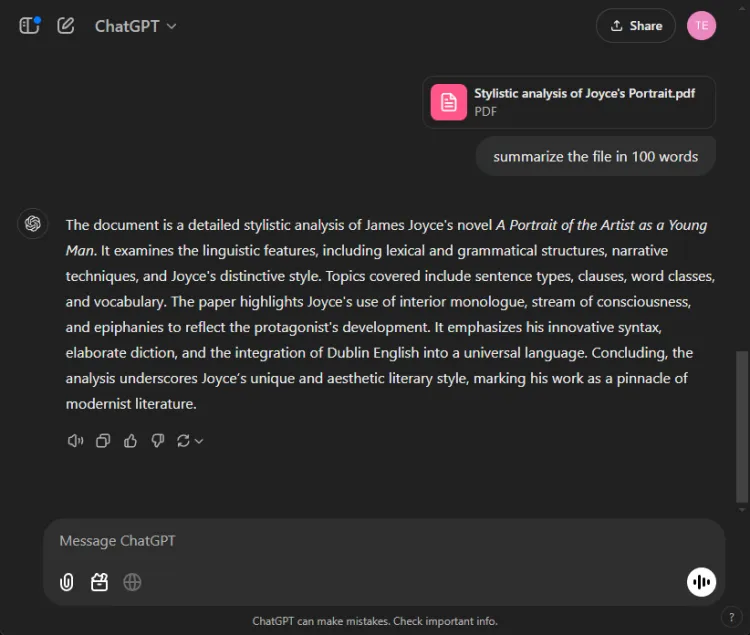
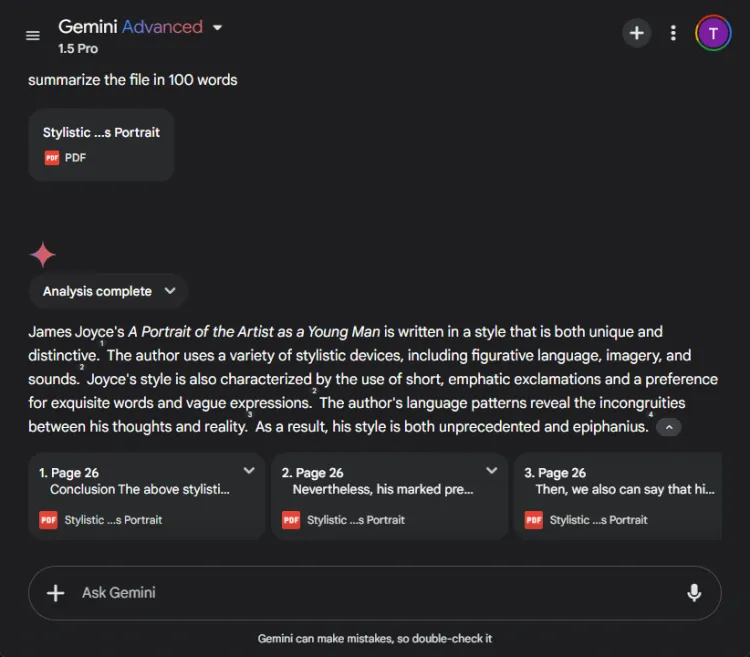
ChatGPT fremviste exceptionelle opsummeringsevner og lavede et komplet resumé inden for grænsen på 100 ord, der omfattede alle vitale punkter. Imidlertid præsenterede den informationen som en enkelt tekstblok uden direkte citater fra papiret.
I modsætning hertil klarede Gemini sig også beundringsværdigt og producerede et resumé på 83 ord understøttet af referencer til specifikke dele af teksten. Mens ChatGPT udmærkede sig i omfang, gav Geminis medtagelse af citater det en vigtig fordel.
Vinder: Gemini
3.’Afslut med et ord’-testen
Denne ligetil opgave krævede at konstruere 10 sætninger, der slutter med ordet “bold.” Opgavens enkelhed gør det bemærkelsesværdigt, at mange modeller kæmper med det.
Hurtig: Provide 10 sentences ending with the word 'ball'.
ChatGPT producerede overraskende kun 3 gyldige sætninger, mens Gemini overgik det med 6 sætninger, der korrekt afsluttede med “bold.” Her er et blik på deres forsøg:
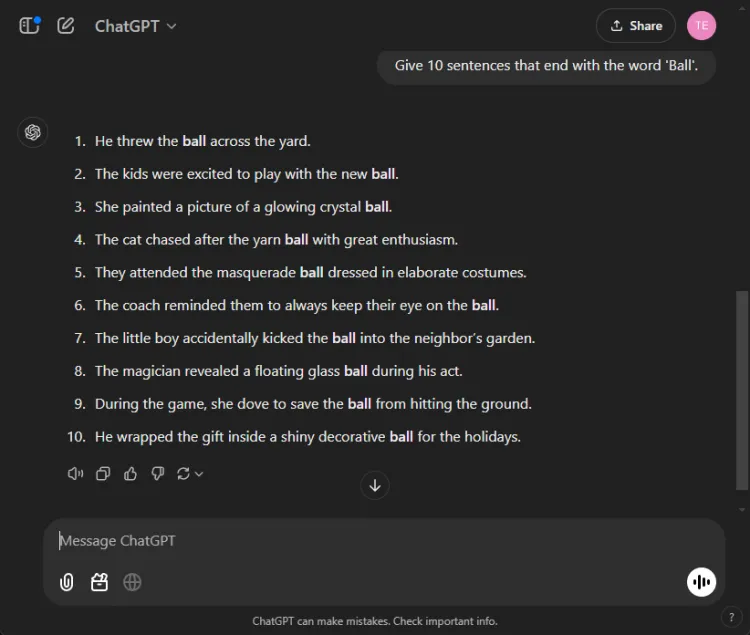
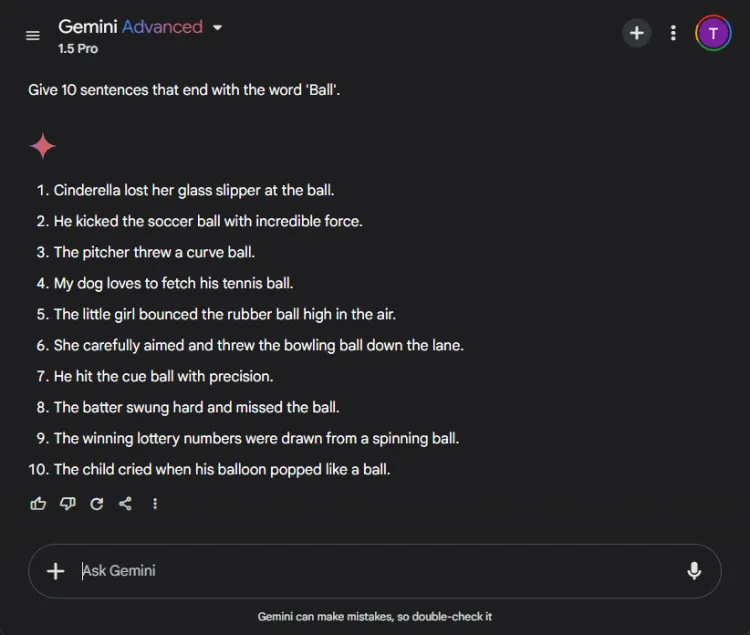
På trods af at begge modeller ikke nåede målet på 10 sætninger, viste Geminis output et overlegent greb om den givne instruktion.
Vinder: Gemini
4. Common Sense Test
Disse test giver en sjov udfordring, da AI ofte fejler her. Vi stillede et ligetil spørgsmål:
Hurtig: If a blue ball falls into the red sea, what color is it now?
Begge modeller leverede præcise svar, der identificerede, at boldens farve ville forblive blå. Nuancerne i deres forklaringer varierede imidlertid:
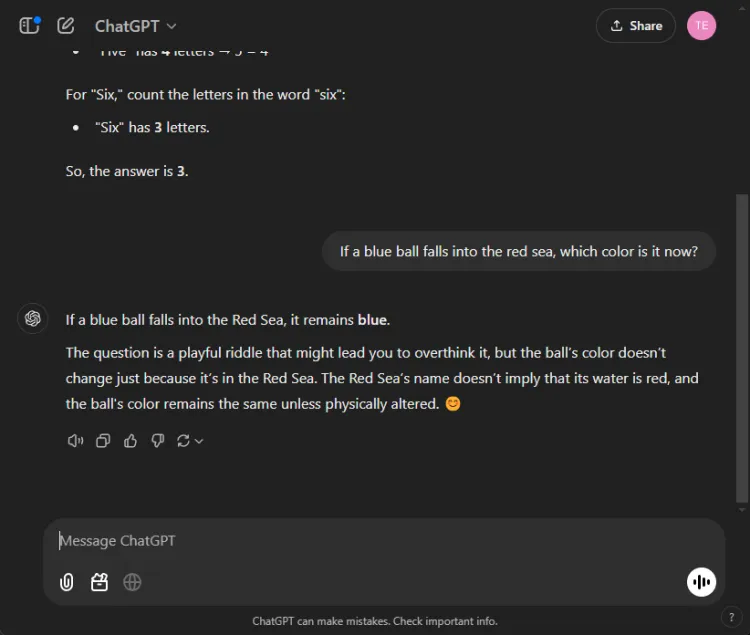
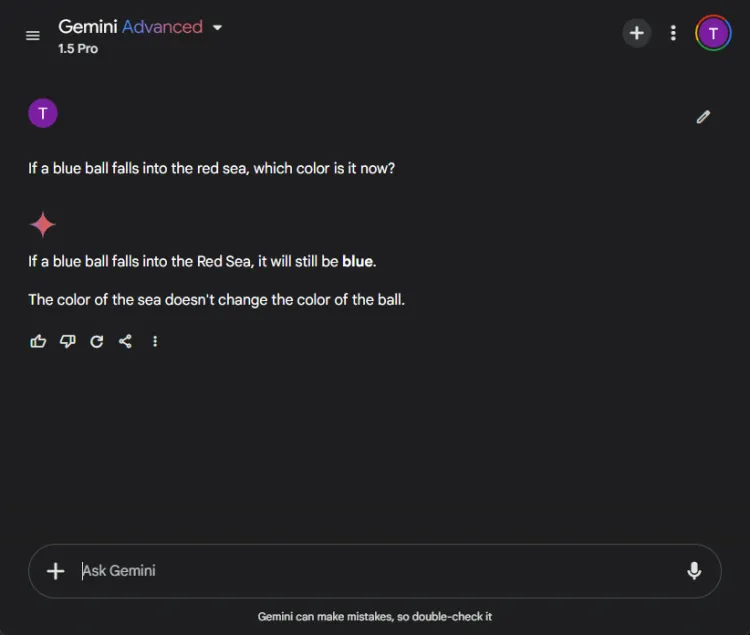
Gemini tilbød et kort svar, mens ChatGPT gav yderligere kontekst. Hvorvidt denne dybde er nødvendig er subjektivt, men begge modeller udmærkede sig ved at identificere boldens farve.
Vinder: slips
5. Kreativitetstest
Udnyttelse af AI til kreativ historiefortælling kan være enormt nyttig. Vi gav hver AI til opgave at komponere en novelle med julemanden, stilet som om den var skrevet af en bedugget Chaucer med 100 ord.
Hurtig: Write a short story about Santa in the style of a drunken Chaucer in 100 words.
Her er deres kreative gengivelser:
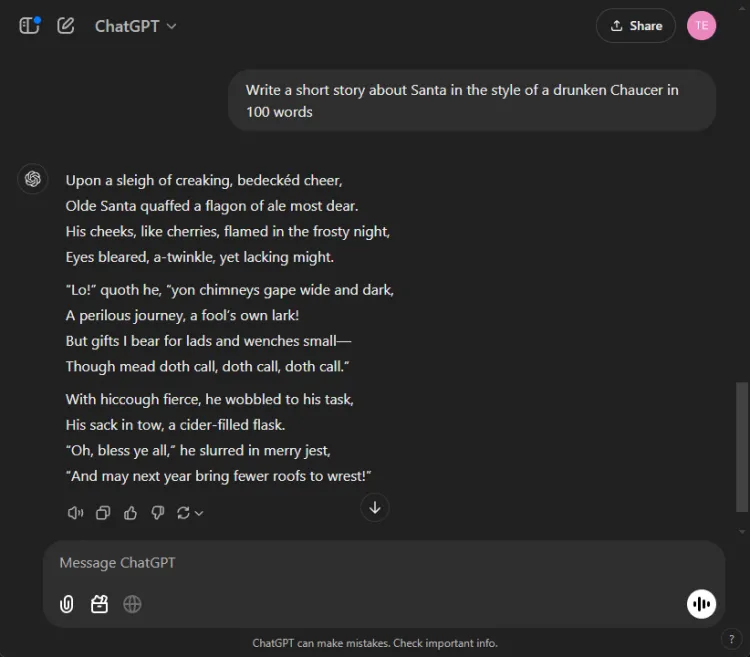
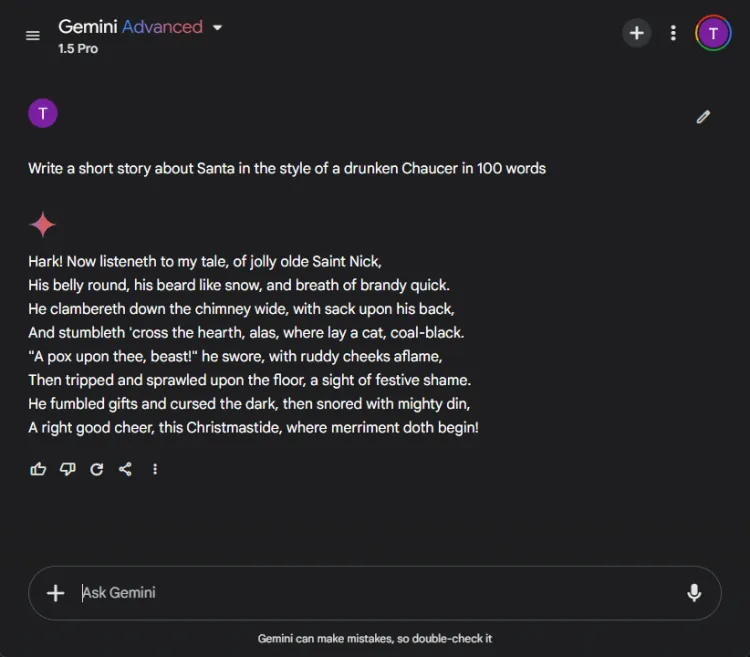
Den subjektive karakter af kreativitet gør det svært at erklære en klar vinder. Især begynder Gemini ofte kreative opgaver med sætningen “Hark”, som er blevet dets foretrukne stilistiske valg. Ikke desto mindre skilte ChatGPTs fortælling sig ud i denne omgang.
Vinder: ChatGPT
6. Billedgenereringstest
Denne test evaluerede de visuelle genereringsmuligheder for hver AI-model. Vi udfordrede dem til at skabe et billede baseret på følgende prompt:
Hurtig: Create an image of a black cat gazing out at fields of barley bathed in evening yellow light, in the style of Vincent Van Gogh.
ChatGPT var et sekund eller to hurtigere, men Geminis endelige billede skildrede scenen med større sofistikering. Selvom begge modeller forstod Van Goghs kunstneriske stil, varierede den subjektive kvalitet af billederne:
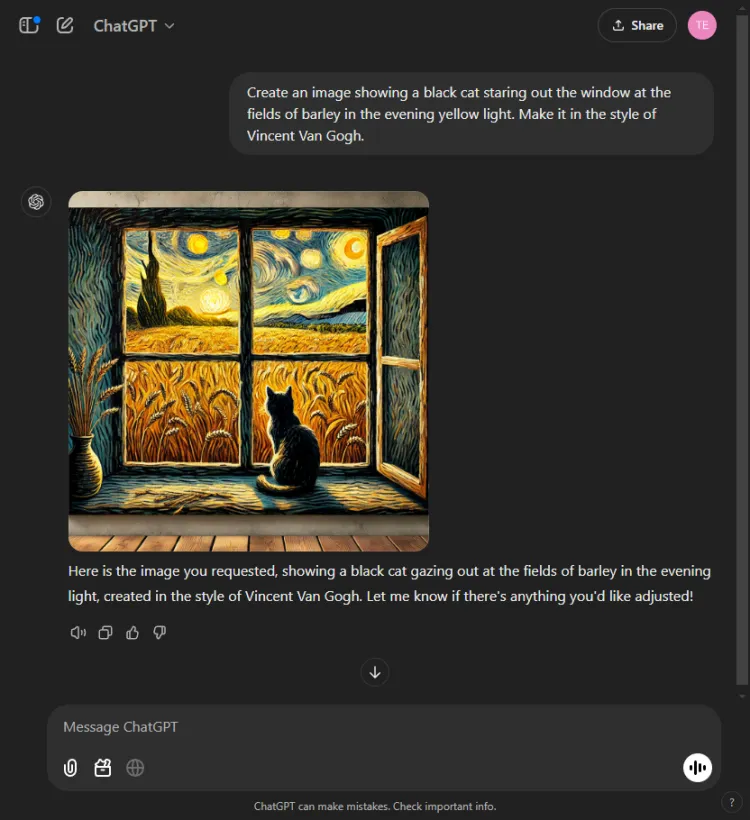
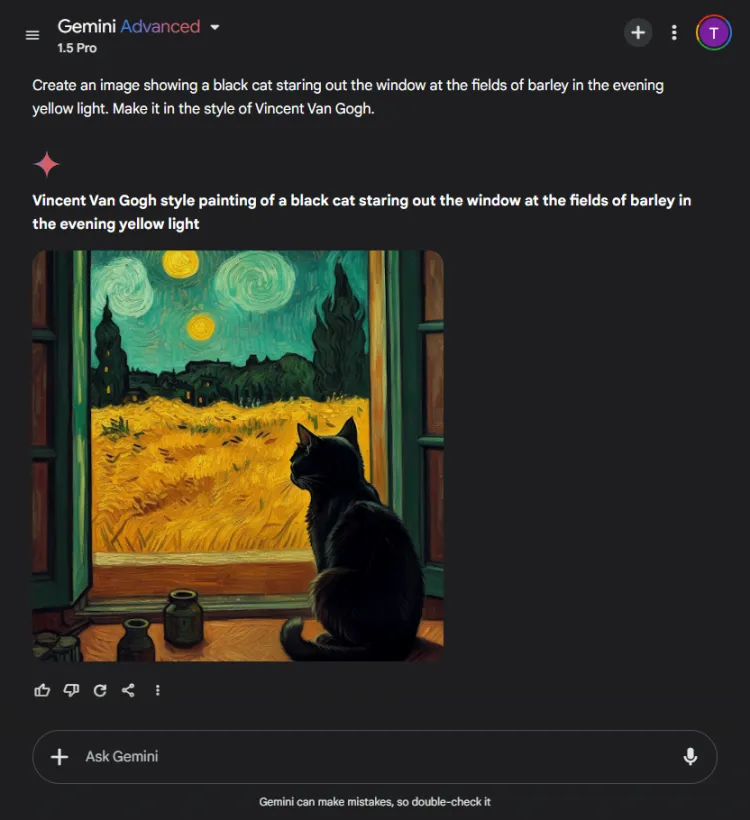
Det er værd at bemærke, at ChatGPT giver mulighed for billedredigering efter generation – en fordel, som Gemini i øjeblikket mangler. Da begge billeder effektivt legemliggjorde Van Goghs signaturstil, afhænger valget af seerens præference, selvom vi hælder til Gemini.
Vinder: Gemini
7. Multimodal generativ test
AI’s færdigheder testes i integrerede tilstande, da de ofte udmærker sig i isolerede opgaver, men kæmper med omfattende. Vi gav begge modeller til opgave at skrive en børnehistorie om sportsånd, mens vi indsatte tre illustrationer undervejs.
Spørgsmål: Skriv en kort børnehistorie om sportsånd og tilføj 3 billeder, hvor det er relevant.
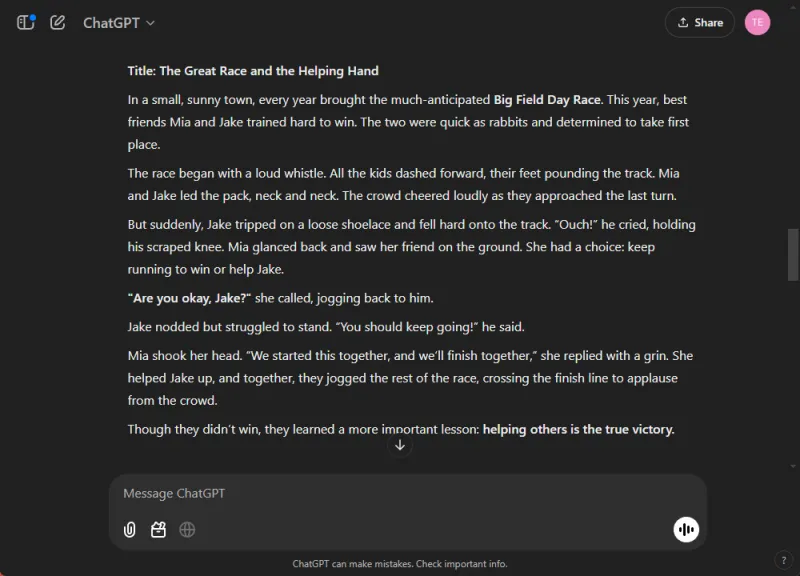
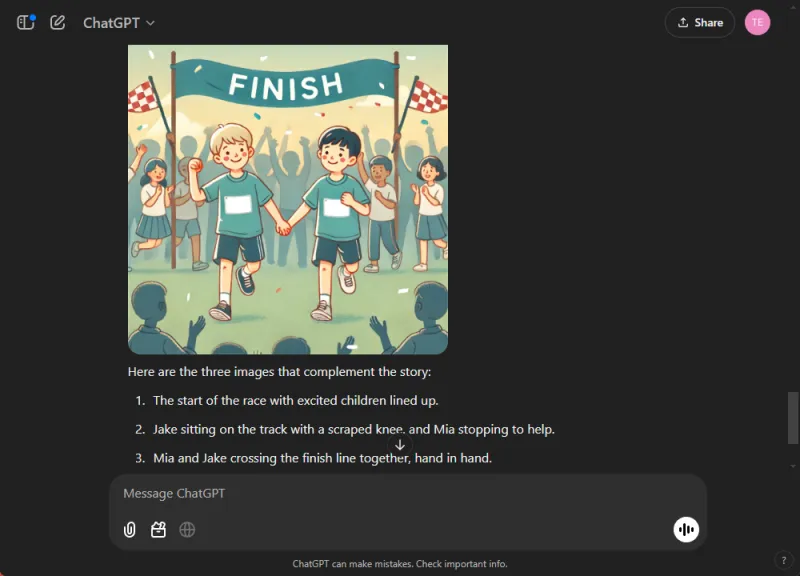
ChatGPT producerede en engagerende fortælling fyldt med moralske refleksioner og problemfrit indbyggede billeder. I modsætning hertil, mens Gemini formåede at skabe en historie, manglede den klarhed og sammenhæng, og den formåede ikke at generere nogen billeder til fortællingen.
Baseret på den overbevisende og let at følge levering var denne beslutning ligetil.
Vinder: ChatGPT.
8. Oversættelsestest
For at måle oversættelseskapaciteten af disse modeller bad vi hver især om at oversætte udvalg fra den hindi-novelle “Grih Daah” af Premchand.
ChatGPT producerede bemærkelsesværdigt effektive oversættelser, forblev tro mod den oprindelige betydning og bibeholdt forfatterens stilistiske integritet:
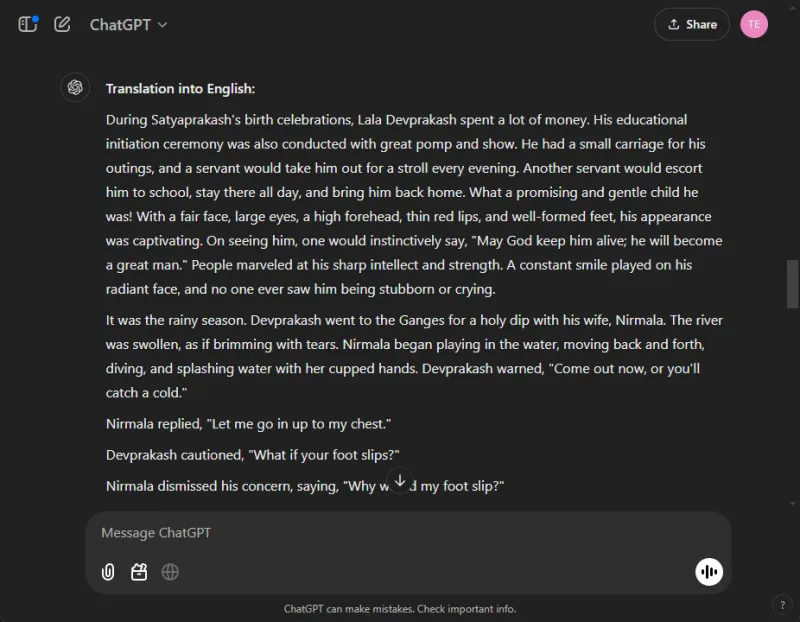
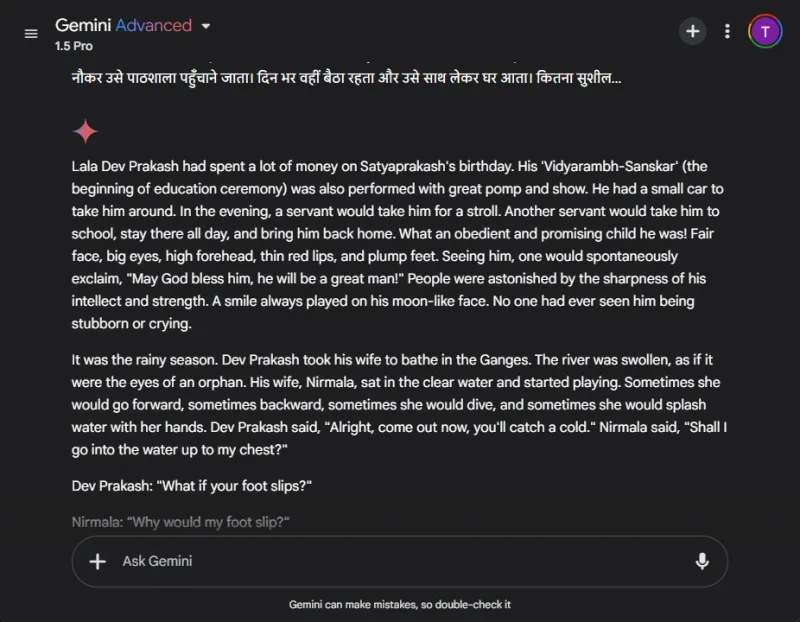
I modsætning hertil kæmpede Gemini i begyndelsen med oversættelsesanmodningen og viste mærkbare forsinkelser i responstiden. Denne uoverensstemmelse i ydeevne er et almindeligt rapporteret problem med Gemini.
Vinder: ChatGPT
9. Kodningstest
For at evaluere deres kodningsevner præsenterede vi et standard optimeringsproblem:
Hurtig: Provide the Python code for the Travelling Salesman Problem.
ChatGPT reagerede effektivt ved at bruge sin integrerede Canvas-tilstand til kodning, som tillod øjeblikkelig kodeudførelse og fejlfindingsfunktioner:
Gemini udmærkede sig på den anden side ved at levere pålidelig kode, men den manglede en interaktiv kodegrænseflade som ChatGPT’s Canvas:
Vinder: ChatGPT
10. Nål i en høstak-test
Denne test udfordrer AI-modeller til at lokalisere specifikke stykker information i et større dokument. Vi brugte det første segment af Pushkins novelle “Kaptajnens datter” og stillede følgende prompt:
Hurtig: Identify which bread Mr. Joe's son ate from the following excerpt.
ChatGPT fandt straks svaret: brunt brød.
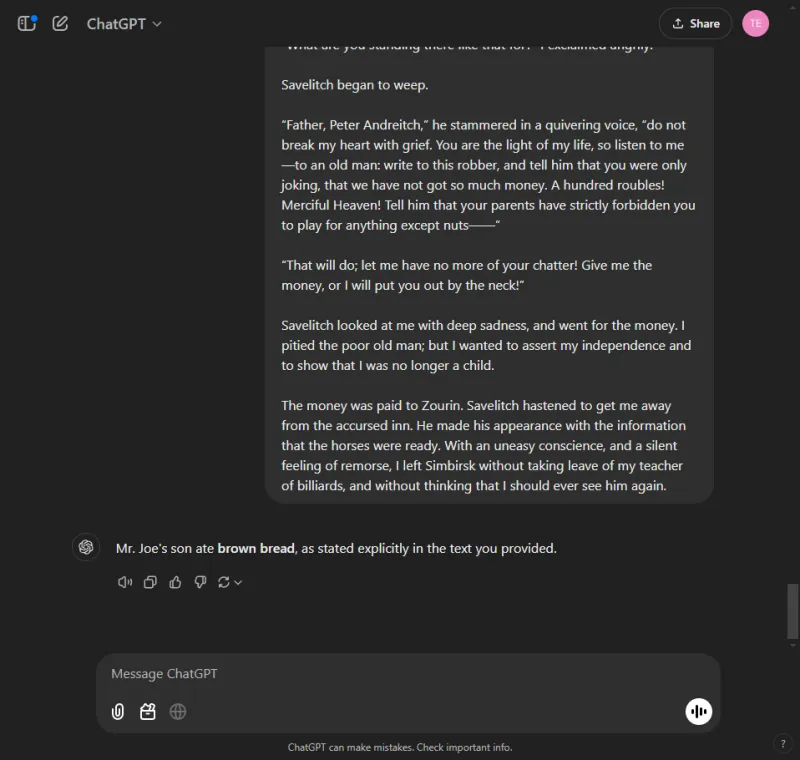
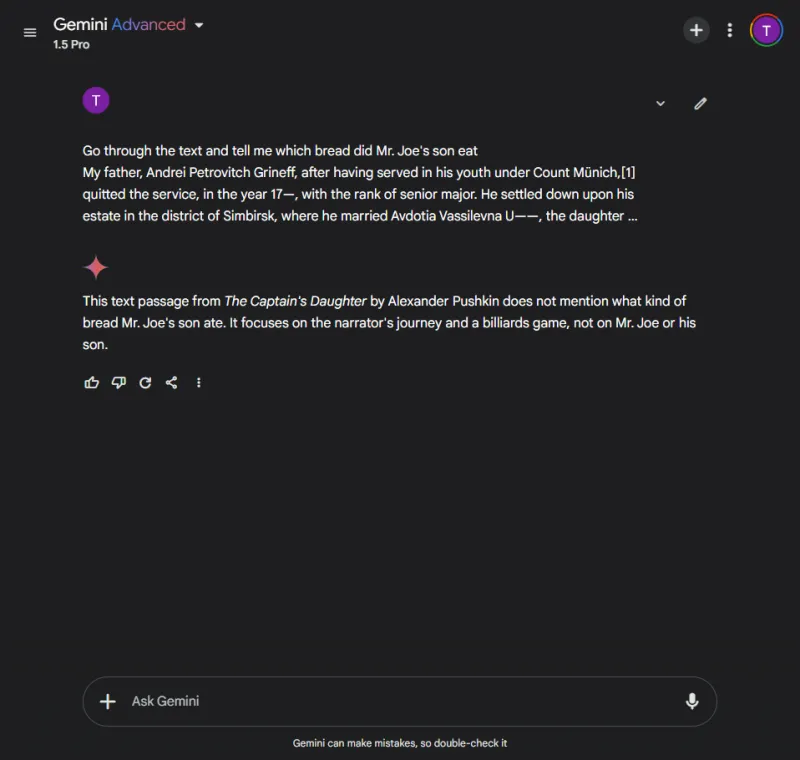
I skarp kontrast lykkedes det ikke Gemini at hente oplysningerne, og kæmpede for at parse de leverede detaljer, hvilket viste en manglende effektivitet i håndteringen af komplekse data.
Vinder: ChatGPT
11. Gæt filmtesten
I denne underholdende runde vurderede vi modellernes billedgenkendelsesfærdigheder ved at identificere et populært filmstillbillede:

Begge modeller navngav filmen nøjagtigt, men ChatGPT formåede at specificere de afbildede karakterer (Colin Farrell og hans æsel), mens Gemini på underholdende vis fejlidentificerede æslet som Colm Doherty.
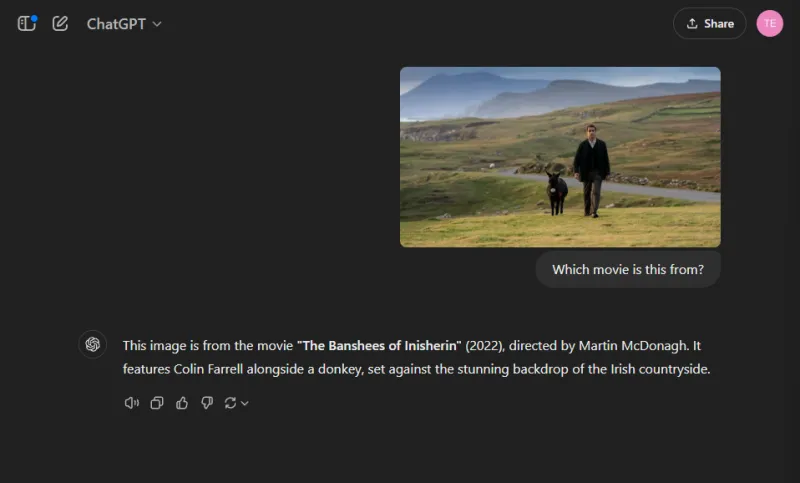
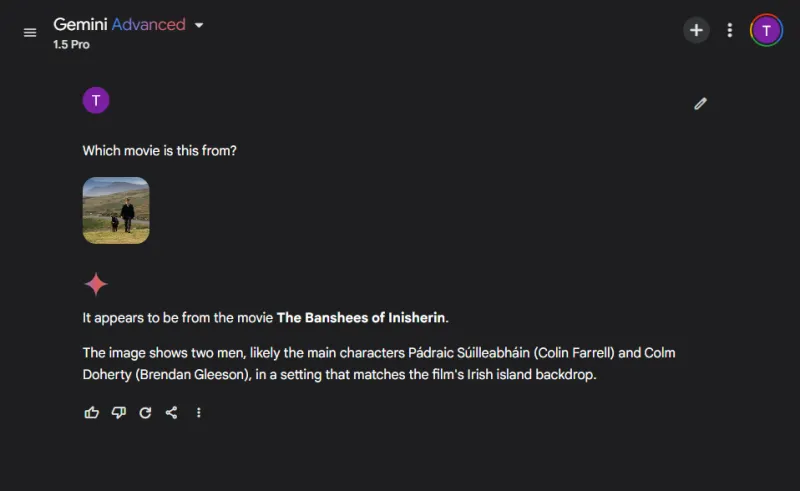
Vinder: ChatGPT
Samlet vinder
Efter at have talt resultaterne, vandt ChatGPTs 4o-model med 6 sejre og 2 uafgjorte resultater, hvilket viser dens robuste ydeevne på tværs af forskellige tests og kompetencer. I mellemtiden præsenterede Geminis 1.5 Pro en prisværdig udfordring, der udmærkede sig i opsummering, billedgenerering og ‘slut med et ord’-opgaven, samt opnåede paritet i både matematik og sund fornuft-evaluering.
I sidste ende overgik ChatGPT Gemini på kritiske områder som kodning, oversættelse, kreativitet, informationssøgning og billedfortolkning. Med ChatGPTs konsekvente pålidelighed skiller den sig ud som den foretrukne AI-partner, selvom Gemini viser potentiale for forbedringer, når prompts er optimeret. I vores evaluering favoriserer resultaterne ChatGPT for dem, der prioriterer troværdighed og effektivitet.
Ofte stillede spørgsmål
1. Hvad er de vigtigste forskelle mellem ChatGPT 4o og Gemini 1.5 Pro?
Mens begge modeller er premium AI-chatbots, har ChatGPT 4o demonstreret overlegen ydeevne inden for kodning, oversættelse og kreative opgaver. Gemini 1.5 Pro udmærker sig dog i opsummering og billedgenerering.
2. Hvilken AI-chatbot er bedre for afslappede brugere?
For afslappede brugere, der søger pålidelighed på tværs af forskellige opgaver, betragtes ChatGPT 4o generelt som det mere pålidelige valg på grund af dets ensartede ydeevne og omfattende muligheder.
3. Kan jeg bruge disse AI-chatbots til forretningsformål?
Absolut! Både ChatGPT 4o og Gemini 1.5 Pro er velegnede til forretningsapplikationer, herunder kundeserviceautomatisering, indholdsskabelse og dataanalyse, hvilket gør dem til værdifulde værktøjer i et professionelt miljø.
Skriv et svar