AI チャットボットの状況は、前例のない速度で進歩しています。ある組織が最新モデルを発表すると、競合他社はすぐにそれに追随し、互いに追い抜こうとします。この競争の激しい分野では、OpenAI の ChatGPT が早い段階でリードしていますが、Gemini などのライバルが急速に勢いを増し、洗練度を高めています。
AI チャットボット開発の現在の最前線に立つのは、ChatGPT と Gemini モデルです。この比較では、ChatGPT の 4o モデルと Gemini の 1.5 Pro に特に焦点を当てます。どちらもさまざまなタスクに合わせてカスタマイズされたプレミアム製品です。
これらの主要モデルの中から選択することは、お客様独自の要件に効果的に対応する上で不可欠です。そこで、当社は一連の厳格なパフォーマンス テストを実施し、どのモデルがさまざまなタスクに優れているかを判断しました。それでは、分析を詳しく見ていきましょう。
1.数学のテスト
私たちの最初の課題は、各モデルの推論能力を測定するために設計された複雑な数学的な謎に取り組むことです。
プロンプト: If 1=3, 2=3, 3=5, 4=4, and 5=4, what is 6?
この謎を解く鍵は、数字の名前の文字を数えることにあります。1 には 3 文字、3 には 5 文字、したがって 6 には 3 文字があります。どちらのモデルも正しい解答にたどり着きましたが、説明はそれぞれ異なっていました。
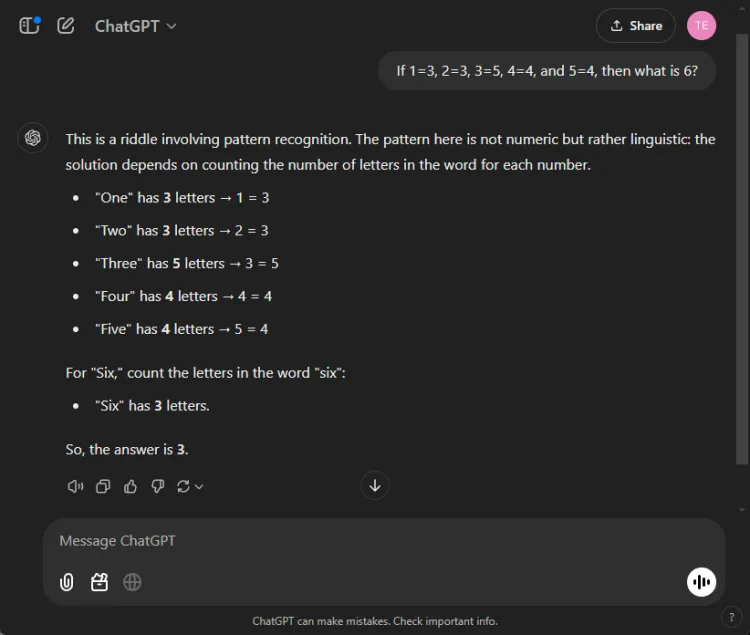
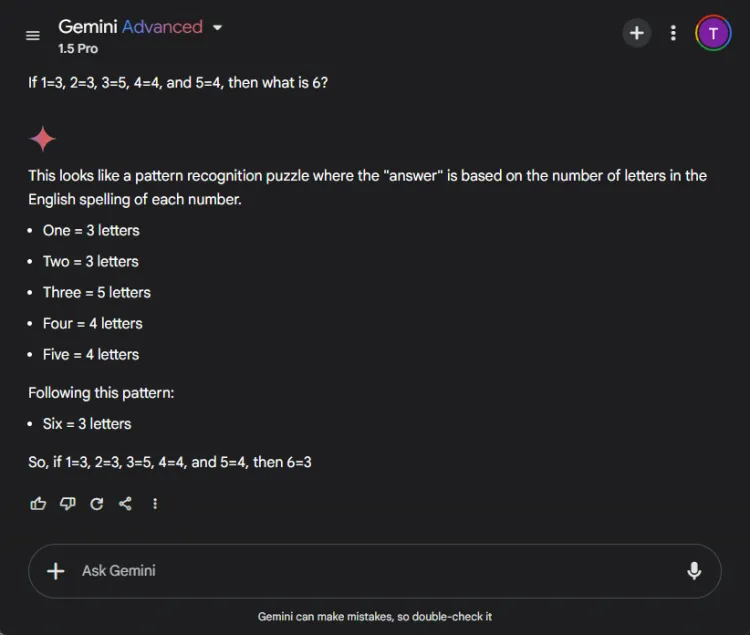
どちらの回答も正確でしたが、ChatGPT は、この演習は数値的理解ではなく言語的理解に依存していると指摘し、もう少し微妙な説明をしました。ただし、この微妙な違いは主観的なものであり、Gemini の正確性を損なうものではありません。
勝者: 引き分け
2.要約テスト
このセグメントでは、各モデルが 27 ページに及ぶ長い研究論文を 100 語未満の簡潔な要約にまとめる能力を評価しました。各モデルが要約にどのような内容を含めたか、または省略したかに焦点が当てられました。
ChatGPT 4o と Gemini 1.5 Pro の出力の違いは次のとおりです。
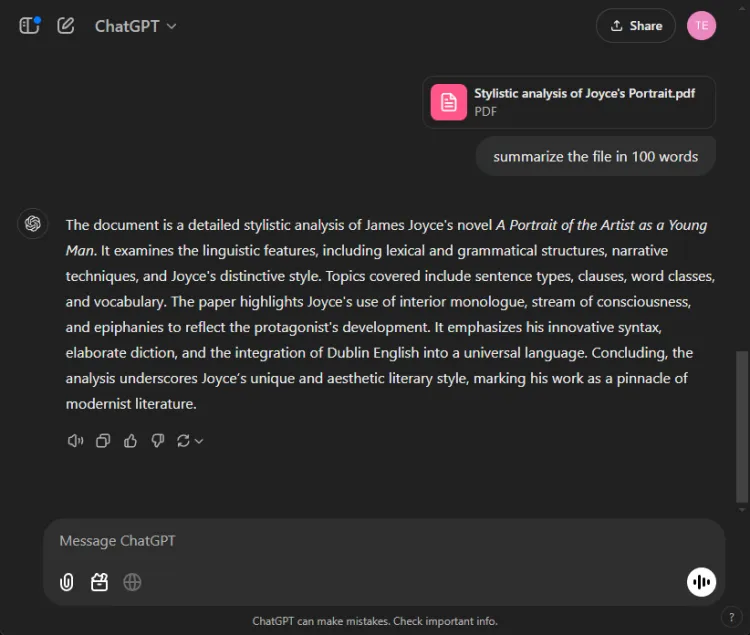
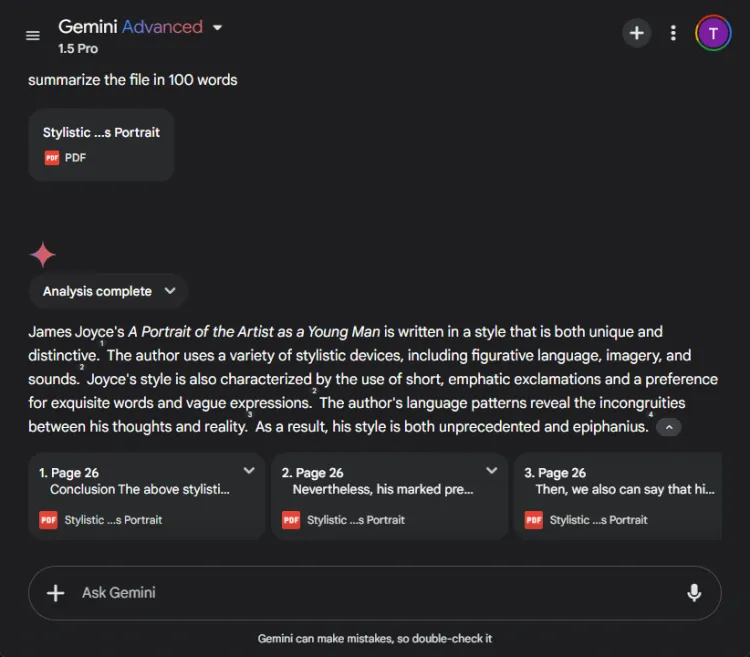
ChatGPT は、100 語の制限内で重要なポイントをすべて網羅した完全な要約を作成し、優れた要約スキルを発揮しました。ただし、論文から直接引用することなく、情報を 1 つのテキスト ブロックとして提示しました。
対照的に、Gemini も優れたパフォーマンスを発揮し、テキストの特定の部分への参照で裏付けられた 83 語の要約を作成しました。ChatGPT は包括性に優れていますが、Gemini が引用を組み込んだことが重要な優位性をもたらしました。
勝者: ジェミニ
3.「単語で終わる」テスト
この単純なタスクでは、「ボール」という単語で終わる 10 個の文を作成する必要がありました。タスクが単純なため、多くのモデルがこれに苦労していることは注目に値します。
プロンプト: Provide 10 sentences ending with the word 'ball'.
ChatGPT が生成した有効な文は意外にも 3 つだけでしたが、Gemini はそれを上回り、正しく「ball」で終わる 6 つの文を生成しました。以下に、その試みを少し紹介します。
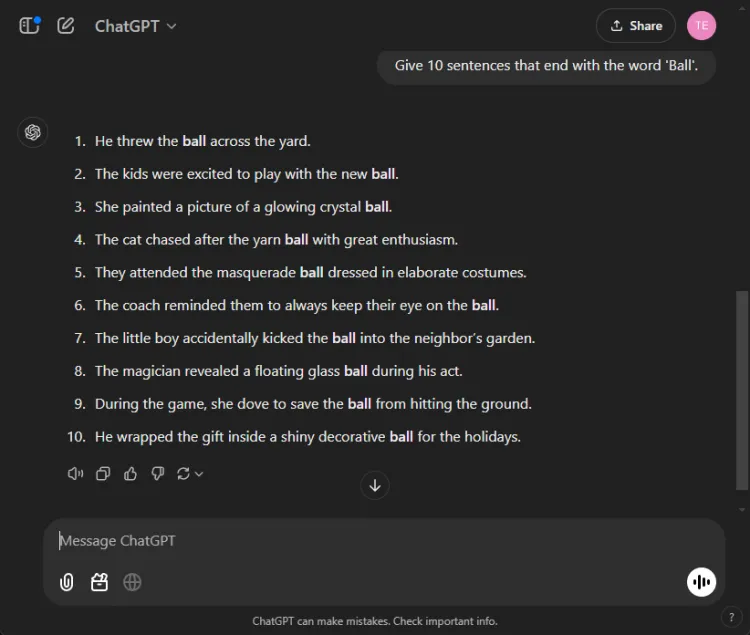
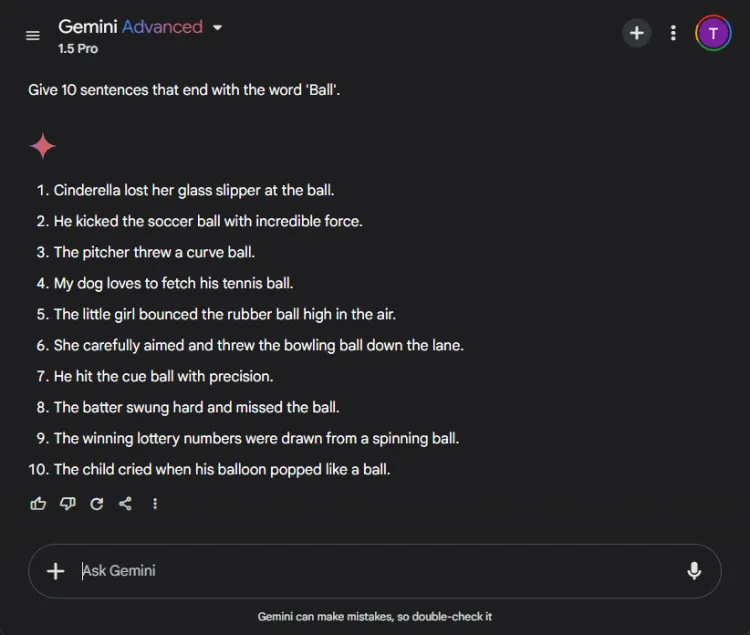
どちらのモデルも 10 文の目標には達しなかったものの、Gemini の出力は与えられた指示を優れた方法で理解していることを示しました。
勝者: ジェミニ
4.常識テスト
AI はここで失敗することが多いため、これらのテストは楽しい課題となります。私たちは率直な質問をしました。
プロンプト: If a blue ball falls into the red sea, what color is it now?
どちらのモデルも正確な答えを出し、ボールの色は青のままであると特定しました。しかし、説明のニュアンスは異なっていました。
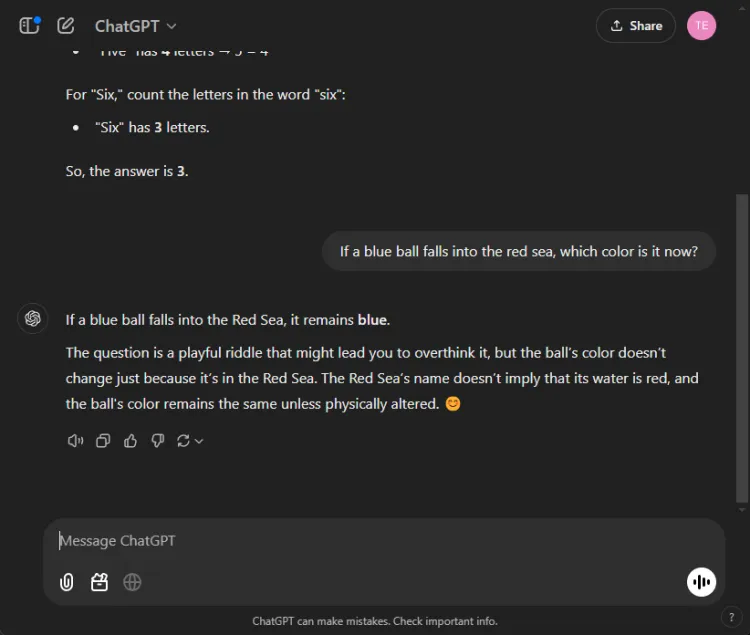
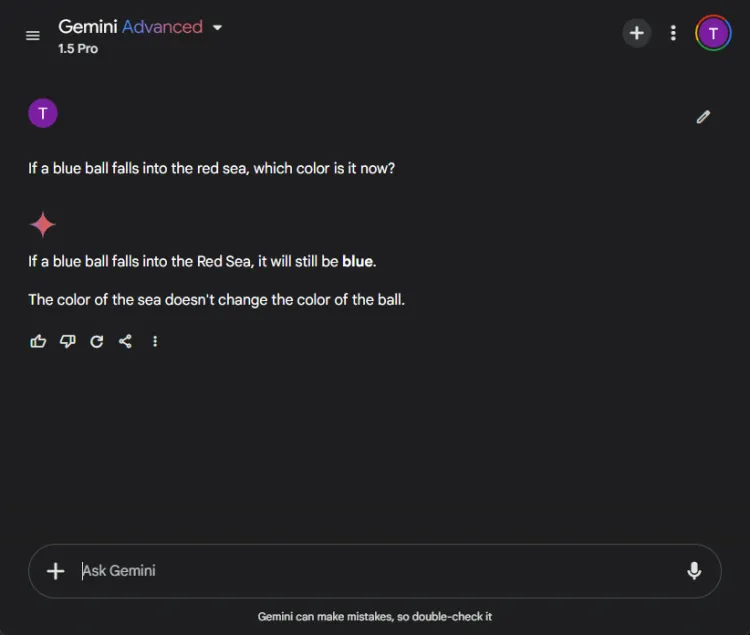
Gemini は簡潔な返答を提供し、ChatGPT は追加のコンテキストを提供しました。この深さが必要かどうかは主観的ですが、どちらのモデルもボールの色の識別に優れていました。
勝者: 引き分け
5.創造性テスト
AI を活用してクリエイティブなストーリーテリングを行うことは、非常に役立ちます。私たちは各 AI に、酔っ払ったチョーサーが 100 語で書いたようなスタイルで、サンタが登場する短編小説を作成するように依頼しました。
プロンプト: Write a short story about Santa in the style of a drunken Chaucer in 100 words.
彼らのクリエイティブなレンダリングは次のとおりです。
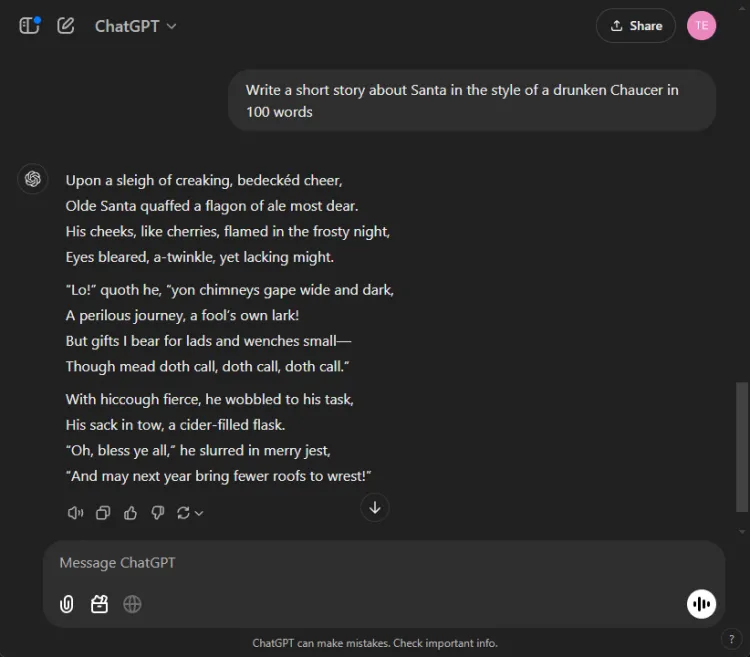
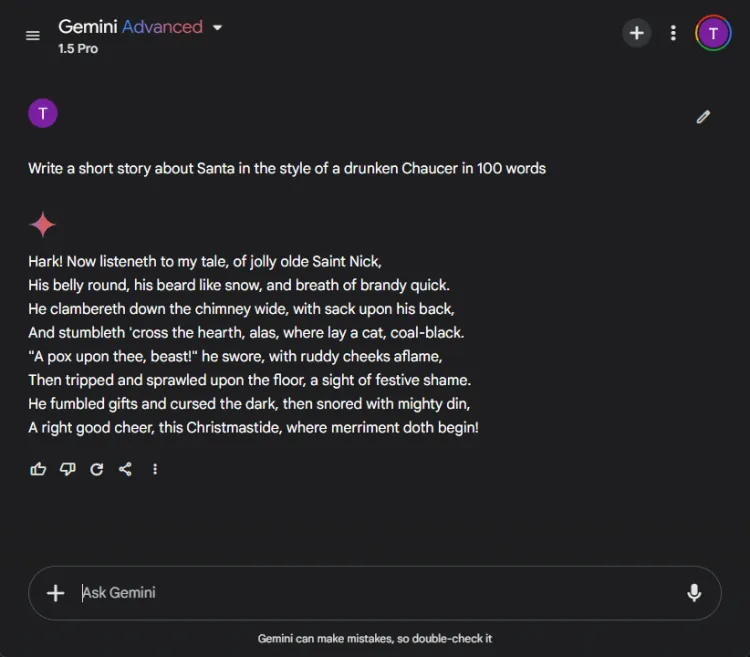
創造性は主観的な性質を持つため、明確な勝者を宣言するのは困難です。特に、Gemini はクリエイティブなタスクを「Hark」というフレーズで始めることが多く、これが Gemini の好みのスタイル選択となっています。それでも、このラウンドでは ChatGPT の物語が際立っていました。
優勝者: ChatGPT
6.画像生成テスト
このテストでは、各 AI モデルのビジュアル生成能力を評価しました。次のプロンプトに基づいて画像を作成するように課題を出しました。
プロンプト: Create an image of a black cat gazing out at fields of barley bathed in evening yellow light, in the style of Vincent Van Gogh.
ChatGPT の方が 1 秒か 2 秒速かったが、Gemini の最終画像の方がシーンをより洗練された形で描写していた。どちらのモデルもゴッホの芸術的スタイルを捉えていたが、画像の主観的な品質は異なっていた。
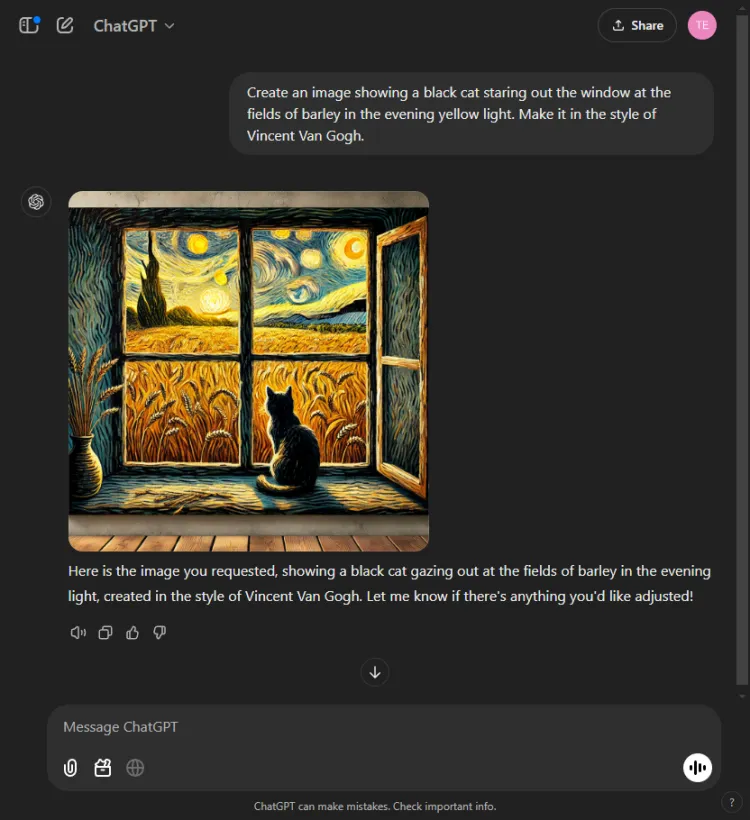
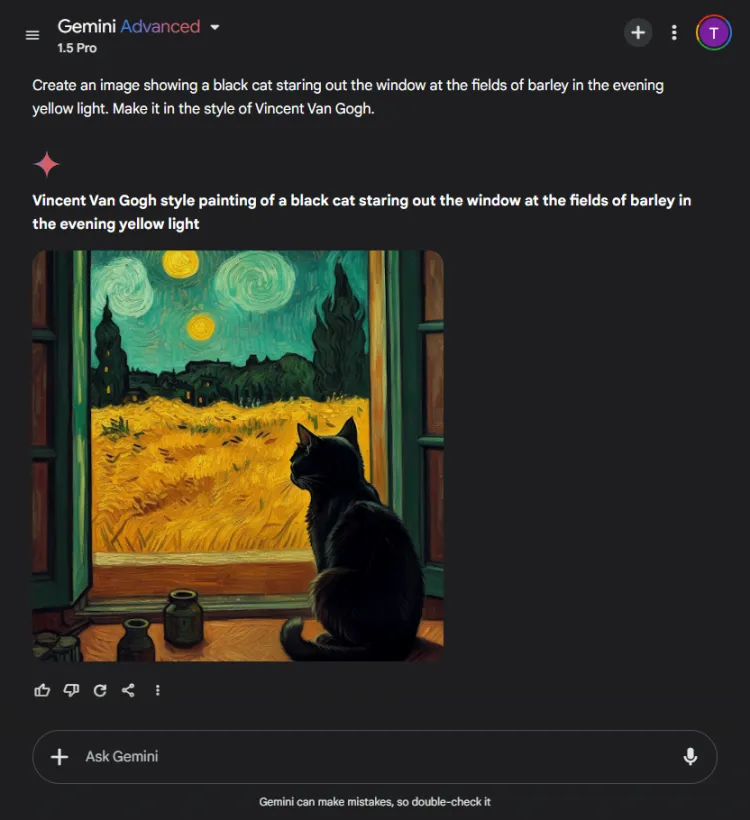
ChatGPT では、画像生成後に編集できるという点も注目に値します。これは、現在 Gemini にはない利点です。どちらの画像もゴッホの特徴的なスタイルを効果的に体現しているため、どちらを選択するかは視聴者の好み次第ですが、私たちは Gemini に傾いています。
勝者: ジェミニ
7.マルチモーダル生成テスト
AI の能力は統合モードでテストされます。AI は個別のタスクでは優れていることが多いのですが、包括的なタスクでは苦戦することが多いからです。私たちは両方のモデルに、スポーツマンシップについての子供向けの物語を書き、その途中で 3 つのイラストを挿入するように指示しました。
プロンプト:スポーツマンシップについての短い子供向けの物語を書き、適切な場所に 3 つの画像を追加します。
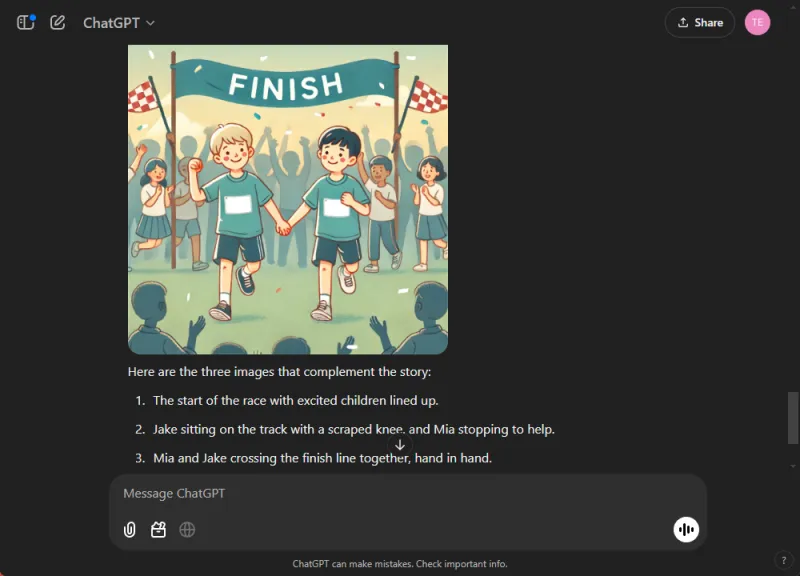
ChatGPT は、道徳的な反省とシームレスに組み込んだ画像を盛り込んだ魅力的な物語を制作しました。対照的に、Gemini はストーリーを作成することはできましたが、明瞭性と一貫性に欠け、物語のイメージを生成できませんでした。
説得力があり、わかりやすい配信に基づいて、この決定は簡単でした。
優勝者: ChatGPT。
8.翻訳テスト
これらのモデルの翻訳能力を測定するために、各モデルに、Premchand 著のヒンディー語短編小説「Grih Daah」の一部を翻訳してもらいました。
ChatGPT は、元の意味に忠実であり、著者の文体の完全性を維持しながら、非常に効果的な翻訳を作成しました。
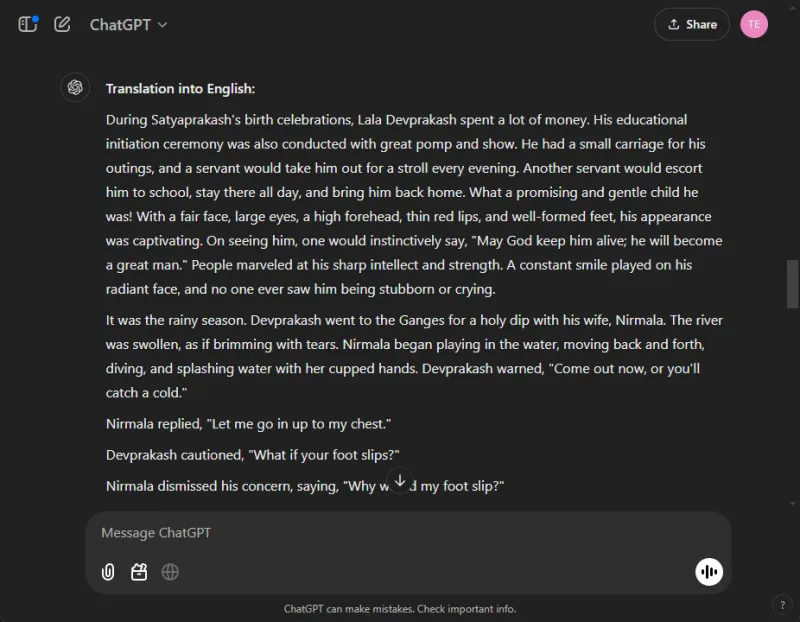
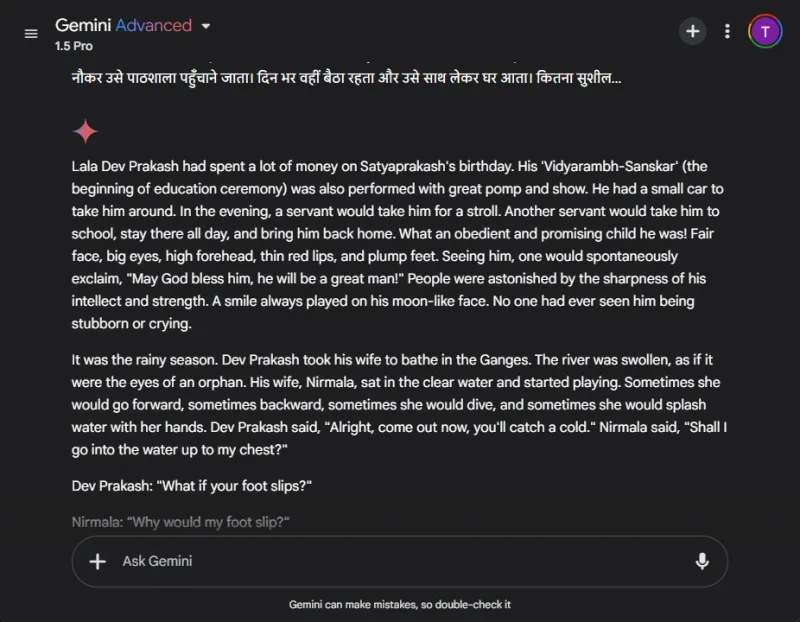
対照的に、Gemini は当初翻訳リクエストに苦労し、応答時間に顕著な遅延を示しました。このパフォーマンスの不一致は、Gemini でよく報告される問題です。
優勝者: ChatGPT
9.コーディングテスト
コーディングスキルを評価するために、標準的な最適化問題を提示しました。
プロンプト: Provide the Python code for the Travelling Salesman Problem.
ChatGPT は、コーディング用の統合キャンバス モードを活用して効率的に応答し、即時のコード実行とデバッグ機能を実現しました。
一方、Gemini は信頼性の高いコードを提供することで優れていましたが、ChatGPT の Canvas のようなインタラクティブなコード インターフェースが欠けていました。
優勝者: ChatGPT
10.針を探すテスト
このテストでは、AI モデルに、大きな文書内の特定の情報を見つけるように要求します。プーシキンの短編小説「大尉の娘」の最初の部分を使用し、次のプロンプトを出しました。
プロンプト: Identify which bread Mr. Joe's son ate from the following excerpt.
ChatGPT はすぐに答えを見つけました: 黒パンです。
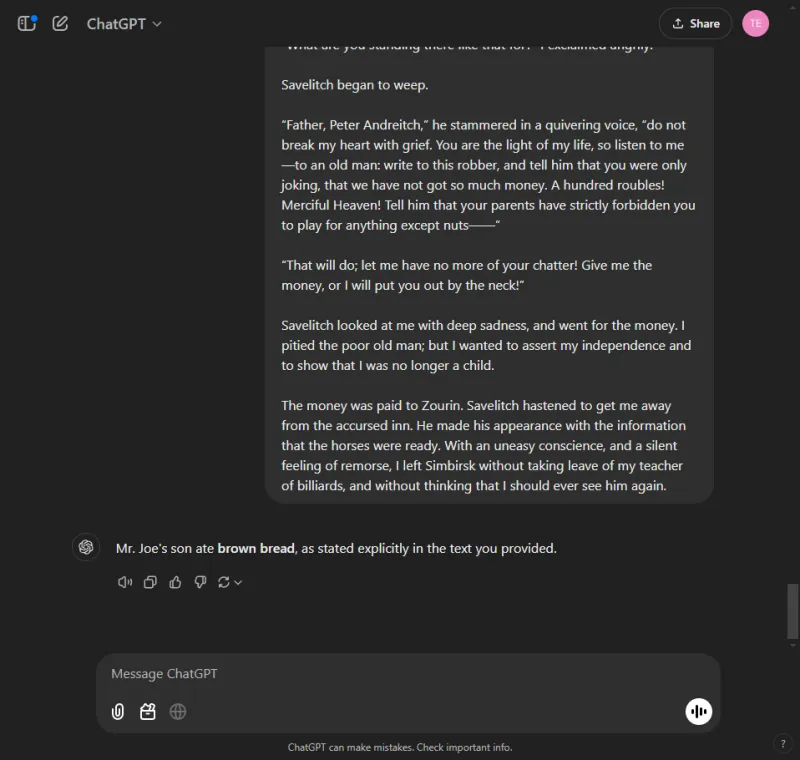
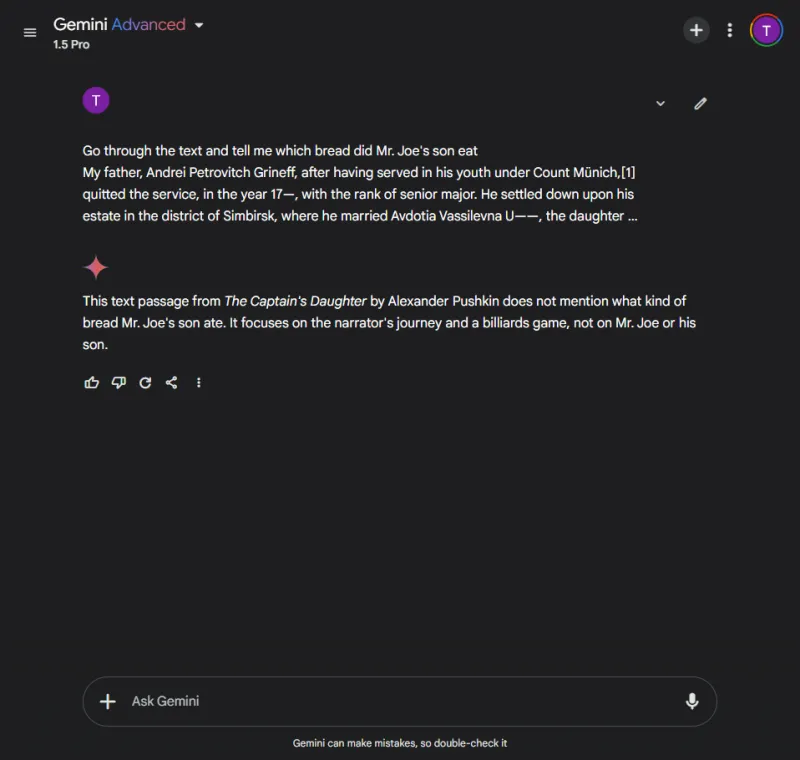
対照的に、Gemini は情報を取得できず、提供された詳細を解析するのに苦労し、複雑なデータの処理に有効性が欠けていることを示しました。
優勝者: ChatGPT
11.映画を当てるテスト
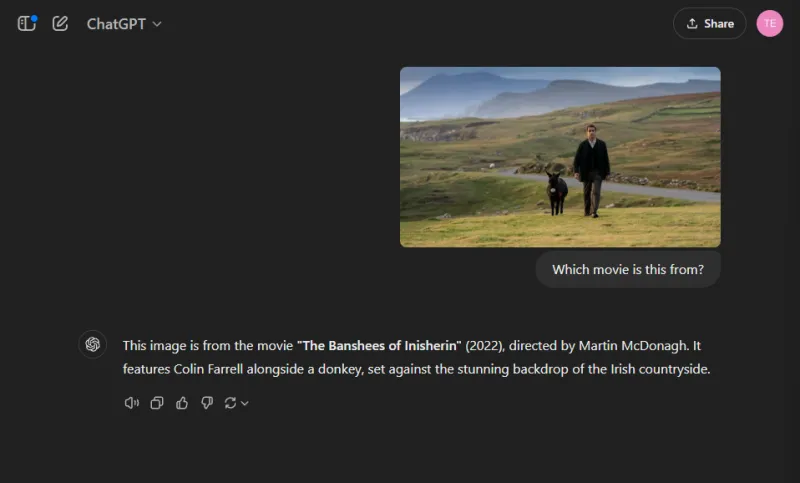
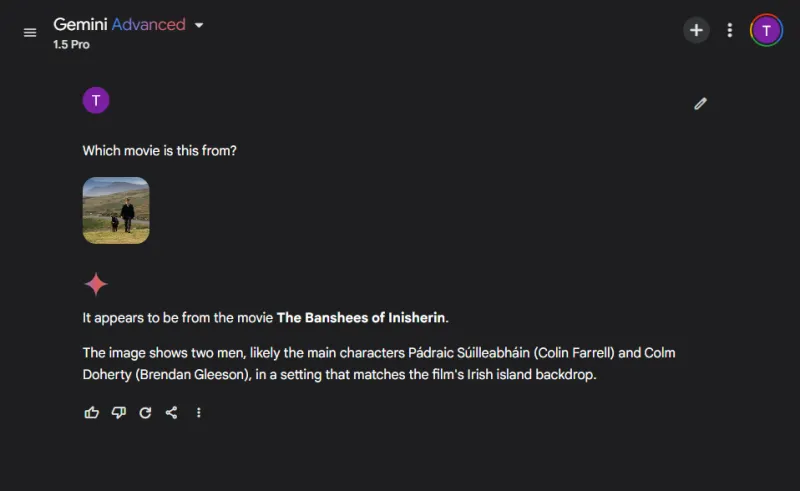
この楽しいラウンドでは、人気映画のスチール写真を識別することで、モデルの画像認識能力を評価しました。

どちらのモデルも映画の名前を正確に挙げましたが、ChatGPT は描かれた登場人物 (コリン・ファレルと彼のロバ) を特定することに成功しましたが、Gemini は面白いことにロバをコルム・ドハティと誤認しました。
優勝者: ChatGPT
総合優勝者
スコアを集計した結果、ChatGPT の 4o モデルが 6 勝 2 引き分けで勝利を収め、さまざまなテストと能力にわたってその強力なパフォーマンスを披露しました。一方、Gemini の 1.5 Pro は、要約、画像生成、および「単語で終わる」タスクで優れた成績を収め、数学と常識の両方の評価で同等の成績を達成するなど、称賛に値する課題を提示しました。
最終的に、ChatGPT はコーディング、翻訳、創造性、情報検索、画像解釈などの重要な分野で Gemini を上回りました。ChatGPT は一貫した信頼性を備えており、プロンプトが最適化されると Gemini が改善する可能性を示しているにもかかわらず、好ましい AI パートナーとして際立っています。私たちの評価では、信頼性と有効性を優先する人にとっては ChatGPT が有利な結果となりました。
よくある質問
1. ChatGPT 4o と Gemini 1.5 Pro の主な違いは何ですか?
どちらのモデルもプレミアム AI チャットボットですが、ChatGPT 4o はコーディング、翻訳、クリエイティブ タスクで優れたパフォーマンスを発揮しています。ただし、Gemini 1.5 Pro は要約と画像生成に優れています。
2.一般ユーザーにとってより適した AI チャットボットはどれですか?
さまざまなタスクにわたって信頼性を求める一般ユーザーにとって、ChatGPT 4o は、一貫したパフォーマンスと広範な機能により、より信頼できる選択肢であると一般的に考えられています。
3.これらの AI チャットボットをビジネス目的で使用できますか?
もちろんです! ChatGPT 4o と Gemini 1.5 Pro はどちらも、顧客サービスの自動化、コンテンツ作成、データ分析などのビジネス アプリケーションに適しており、プロフェッショナルな環境で役立つツールです。
コメントを残す