AI 챗봇의 풍경은 전례 없는 속도로 발전하고 있습니다.한 조직이 최신 모델을 공개하자마자 경쟁사들은 재빨리 뒤를 따르며 서로를 앞지르려고 노력합니다. OpenAI의 ChatGPT가 이 경쟁적인 경기장에서 일찍 선두를 차지했음에도 불구하고 Gemini와 같은 경쟁사들은 빠르게 주목을 받고 정교해졌습니다.
현재 AI 챗봇 개발의 선두 주자에는 ChatGPT와 Gemini 모델이 있습니다.이 비교에서 우리는 특히 ChatGPT의 4o 모델과 Gemini의 1.5 Pro에 초점을 맞춥니다.둘 다 다양한 작업에 맞게 맞춤화된 프리미엄 제품입니다.
이러한 선도적 모델 중에서 선택하는 것은 고유한 요구 사항을 효과적으로 해결하는 데 필수적입니다.따라서 우리는 다양한 작업에서 어떤 모델이 뛰어난지 알아내기 위해 일련의 엄격한 성능 테스트를 수행했습니다.분석에 들어가 봅시다!
1.수학 시험
첫 번째 과제는 각 모델의 추론 능력을 측정하도록 설계된 복잡한 수학적 수수께끼를 해결하는 것입니다.
즉각적인: If 1=3, 2=3, 3=5, 4=4, and 5=4, what is 6?
이 수수께끼를 푸는 열쇠는 숫자 이름의 글자를 세는 데 있습니다.하나는 세 글자이고, 세 개는 다섯 글자이며, 결과적으로 여섯은 세 글자입니다.두 모델 모두 올바른 해결책에 도달했지만, 설명은 다양했습니다.
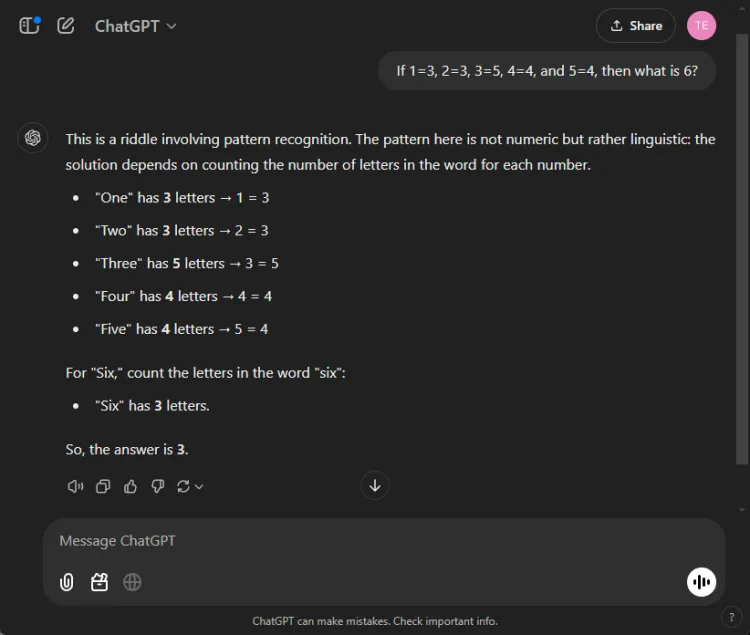
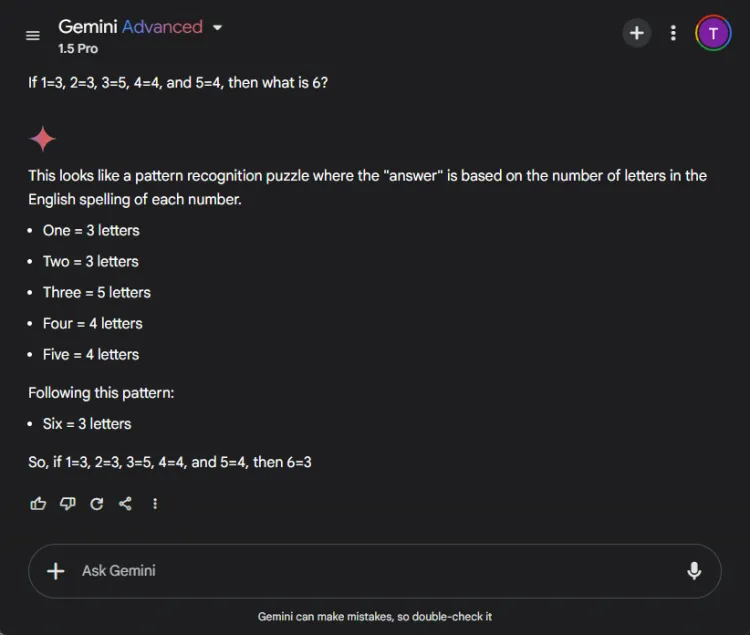
두 답변 모두 정확했지만, ChatGPT는 이 연습이 숫자적 이해보다는 언어적 이해에 의존한다는 점을 지적하며 약간 더 미묘한 설명을 제공했습니다.그러나 이 미묘한 차이는 주관적이며 Gemini의 정확성을 떨어뜨리지 않습니다.
승자: 동점
2.요약 테스트
이 세그먼트는 각 모델이 27페이지 분량의 긴 연구 논문을 100단어 미만의 간결한 요약으로 축약하는 능력을 평가했습니다.초점은 각 모델이 요약에 포함하거나 생략한 내용에 맞춰졌습니다.
ChatGPT 4o와 Gemini 1.5 Pro의 출력은 다음과 같습니다.
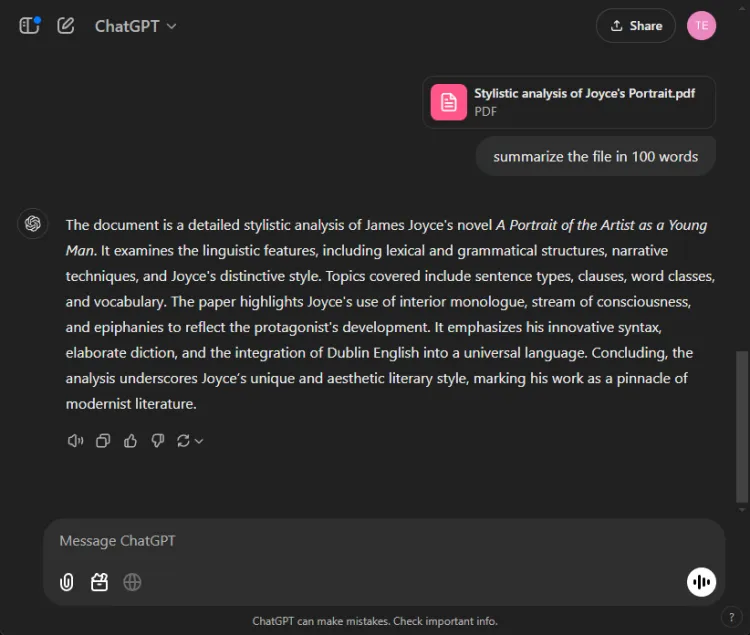
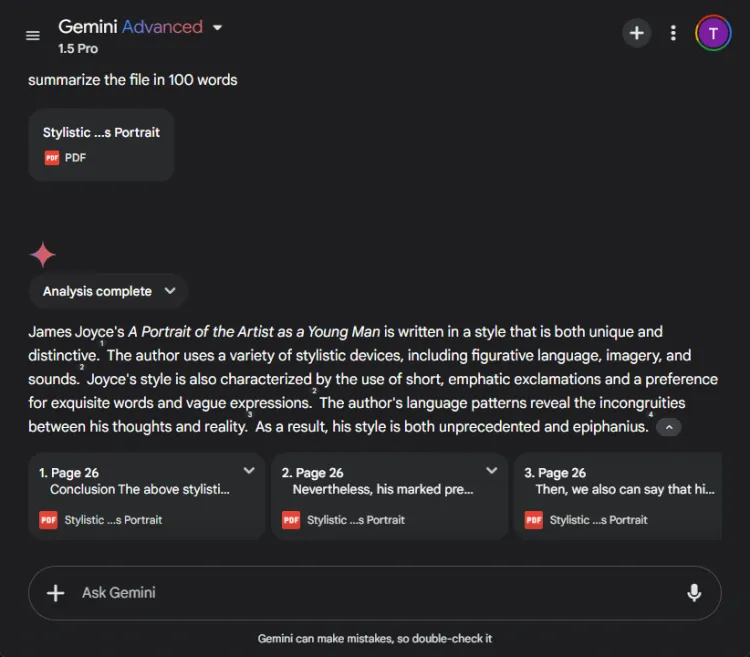
ChatGPT는 뛰어난 요약 기술을 보여주며 100단어 제한 내에서 모든 중요한 요점을 포함하는 완전한 요약을 작성했습니다.그러나 논문에서 직접 인용하지 않고 단일 텍스트 블록으로 정보를 제시했습니다.
대조적으로, Gemini도 훌륭하게 수행하여 텍스트의 특정 부분에 대한 참조로 뒷받침되는 83단어 요약을 작성했습니다. ChatGPT가 포괄성에서 뛰어났지만, Gemini의 인용문 포함은 중요한 우위를 제공했습니다.
승자: 쌍둥이자리
3.’단어로 끝내기’ 테스트
이 간단한 작업에는 “공”이라는 단어로 끝나는 10개의 문장을 구성하는 것이 필요했습니다.작업이 간단하기 때문에 많은 모델이 이 작업에서 어려움을 겪는다는 점이 주목할 만합니다.
즉각적인: Provide 10 sentences ending with the word 'ball'.
ChatGPT는 놀랍게도 유효한 문장을 3개만 생성했지만 Gemini는 “ball”로 올바르게 끝나는 문장 6개를 생성해 이를 능가했습니다.다음은 그들의 시도를 간략히 살펴본 것입니다.
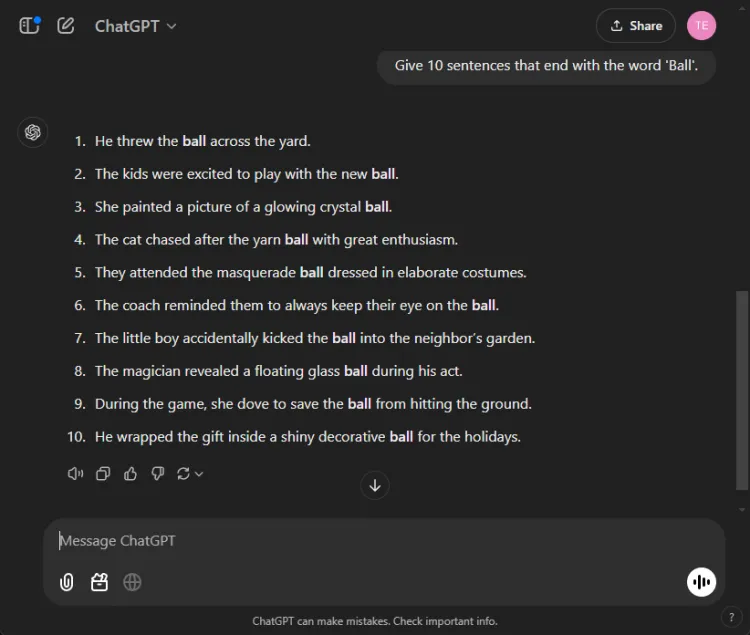
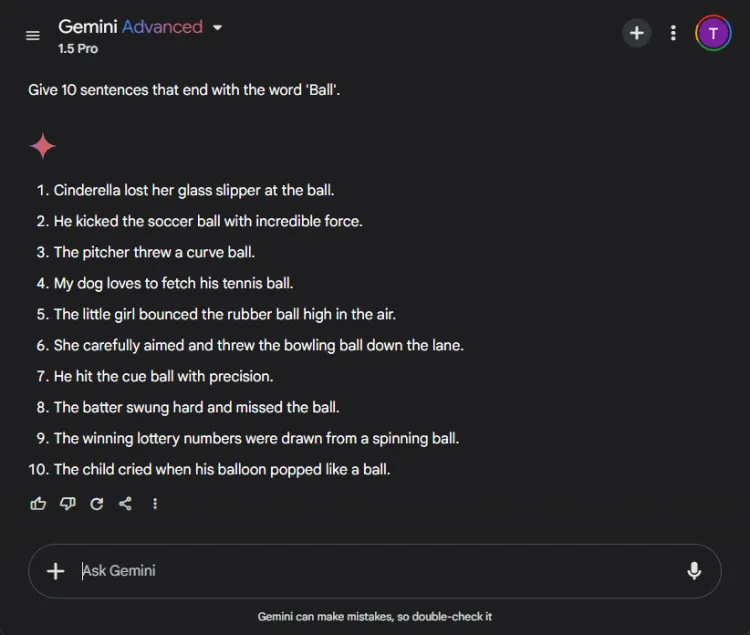
두 모델 모두 10문장 목표에는 미치지 못했지만, 쌍둥이 자리의 출력은 주어진 지시를 훨씬 더 잘 이해했음을 보여주었습니다.
승자: 쌍둥이자리
4.상식 테스트
이러한 테스트는 AI가 종종 실수를 하기 때문에 재미있는 도전을 제시합니다.우리는 간단한 질문을 던졌습니다.
즉각적인: If a blue ball falls into the red sea, what color is it now?
두 모델 모두 정확한 답변을 제공했으며, 공의 색상이 파란색으로 유지될 것이라고 식별했습니다.그러나 설명의 뉘앙스는 다양했습니다.
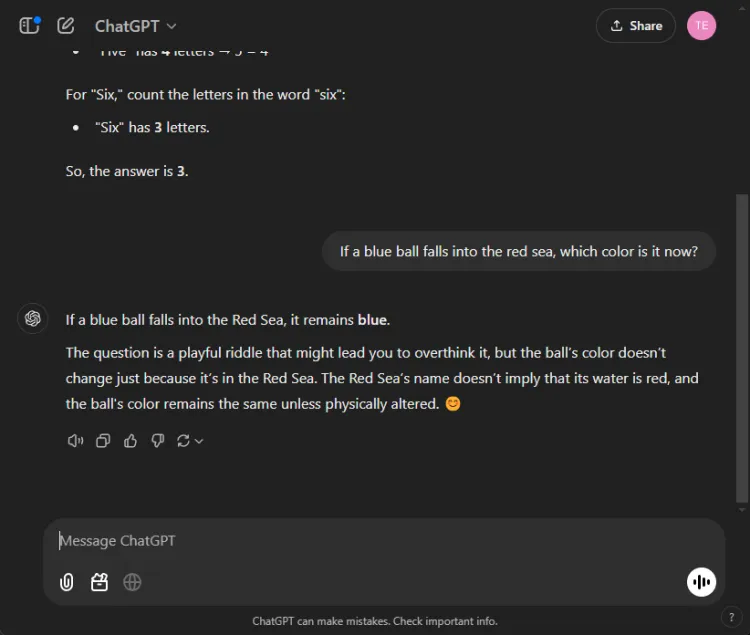
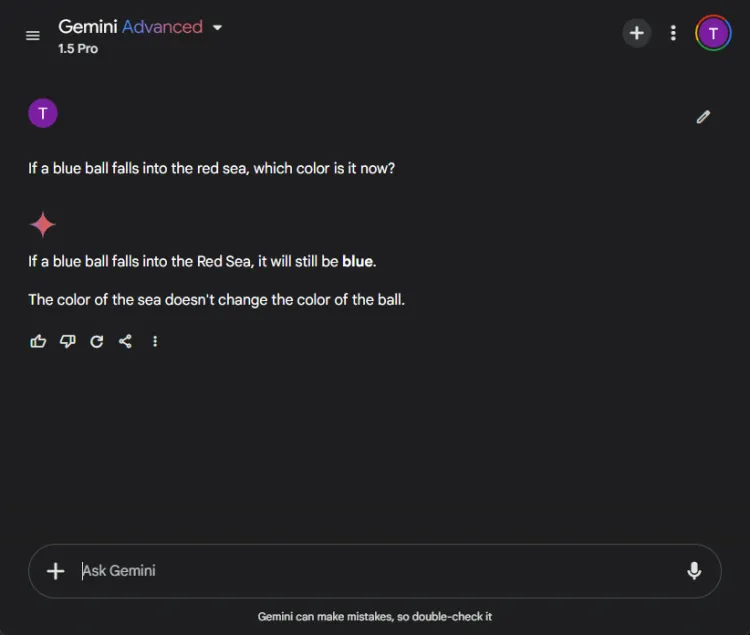
Gemini는 간단한 답변을 제공했고, ChatGPT는 추가적인 맥락을 제공했습니다.이 깊이가 필요한지는 주관적이지만, 두 모델 모두 공의 색상을 식별하는 데 탁월했습니다.
승자: 동점
5.창의성 테스트
AI를 창의적인 스토리텔링에 활용하는 것은 엄청나게 도움이 될 수 있습니다.우리는 각 AI에게 마치 취한 초서가 100단어로 쓴 것처럼 스타일링된 산타를 특징으로 하는 단편 소설을 쓰도록 했습니다.
즉각적인: Write a short story about Santa in the style of a drunken Chaucer in 100 words.
그들의 창의적인 렌더링은 다음과 같습니다.
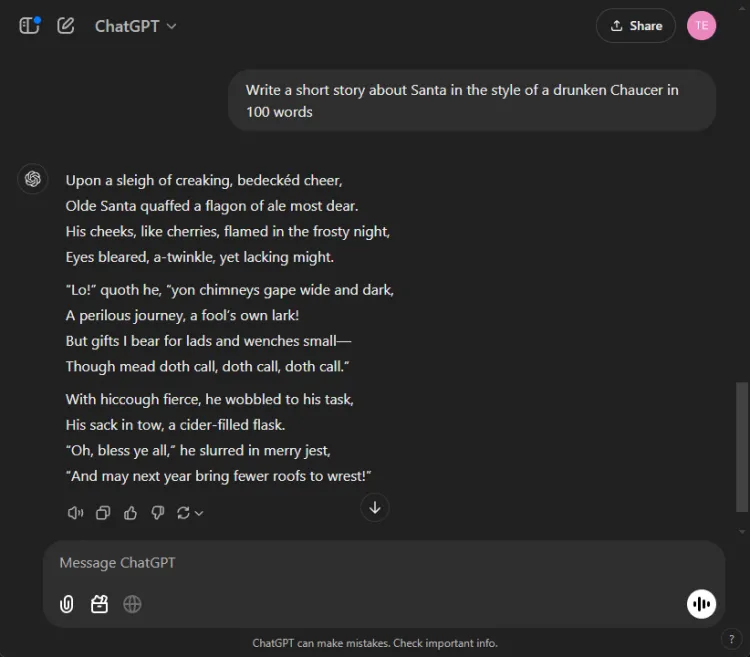
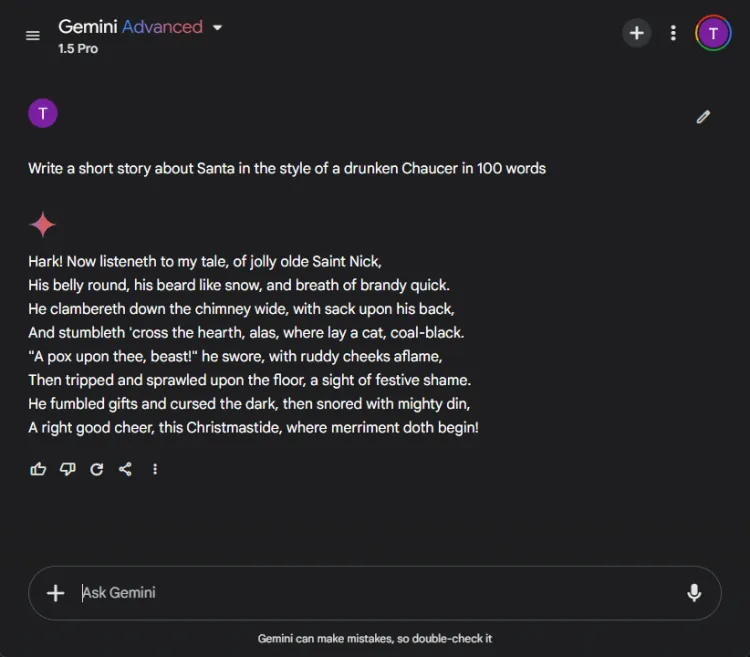
창의성의 주관적 특성으로 인해 명확한 승자를 선언하기 어렵습니다.특히, 쌍둥이자리는 종종 창의적인 작업을 “Hark”라는 문구로 시작하는데, 이는 선호하는 스타일 선택이 되었습니다.그럼에도 불구하고, ChatGPT의 내러티브는 이 라운드에서 두드러졌습니다.
우승자: ChatGPT
6.이미지 생성 테스트
이 테스트는 각 AI 모델의 시각적 생성 능력을 평가했습니다.우리는 그들에게 다음 프롬프트에 따라 이미지를 만들도록 도전했습니다.
즉각적인: Create an image of a black cat gazing out at fields of barley bathed in evening yellow light, in the style of Vincent Van Gogh.
ChatGPT는 1~2초 정도 더 빨랐지만, Gemini의 최종 이미지는 장면을 더 정교하게 묘사했습니다.두 모델 모두 반 고흐의 예술적 스타일을 파악했지만, 이미지의 주관적 품질은 다양했습니다.
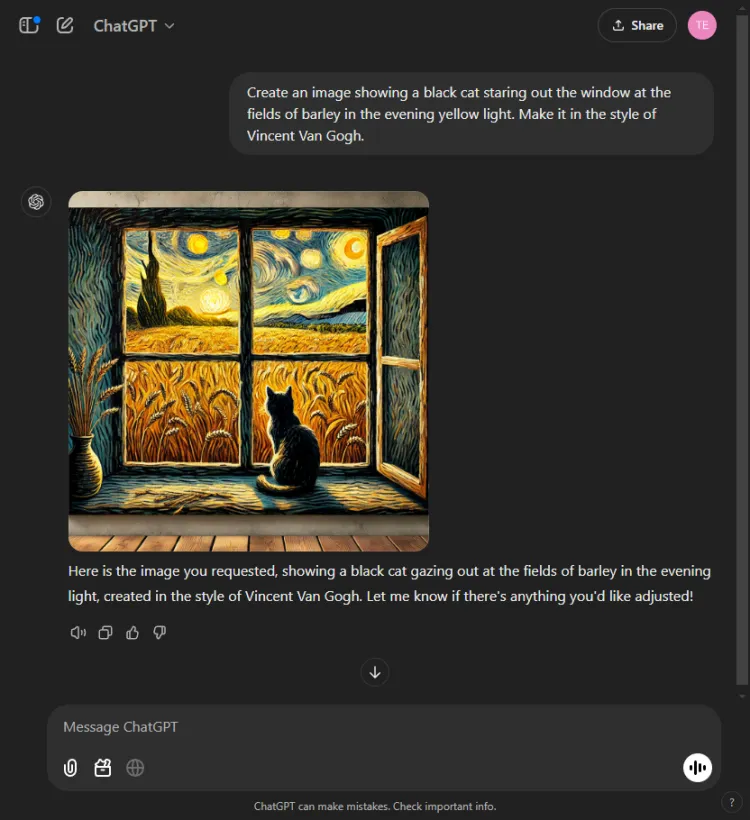
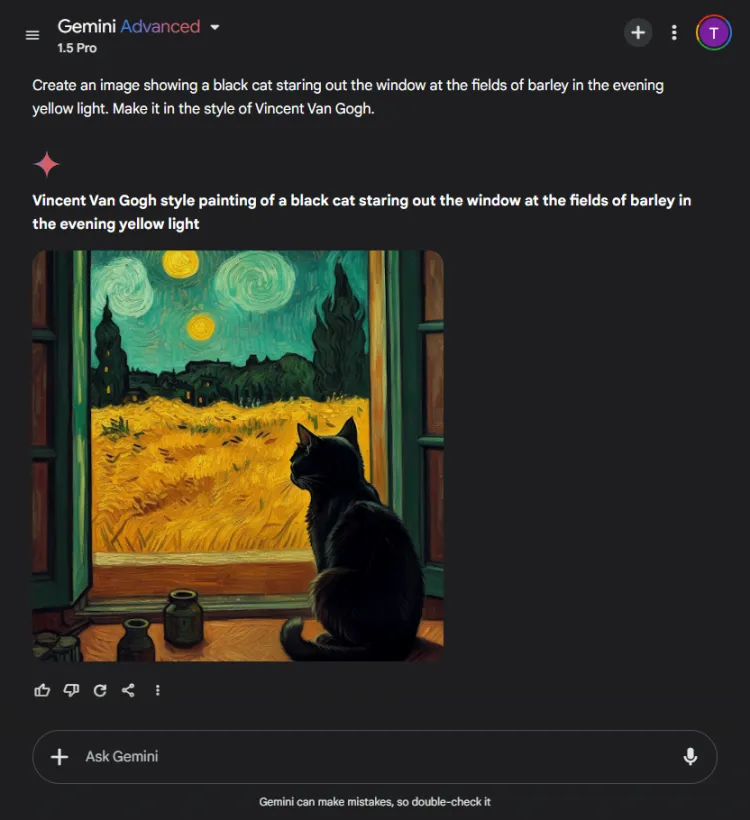
ChatGPT는 생성 후 이미지 편집을 허용한다는 점에 주목할 가치가 있습니다. Gemini에는 현재 없는 이점입니다.두 이미지 모두 반 고흐의 시그니처 스타일을 효과적으로 구현했기 때문에 선택은 시청자의 선호도에 달려 있지만, 우리는 Gemini를 선호합니다.
승자: 쌍둥이자리
7.멀티모달 생성 테스트
AI의 능숙도는 통합 모드에서 테스트됩니다. AI는 종종 고립된 작업에서는 뛰어나지만 포괄적인 작업에서는 어려움을 겪습니다.우리는 두 모델 모두에게 스포츠맨십에 대한 어린이 이야기를 쓰도록 했고, 그 과정에서 세 개의 그림을 삽입했습니다.
프롬프트: 스포츠맨십에 대한 짧은 어린이 이야기를 쓰고 적절한 곳에 3개의 이미지를 추가하세요.
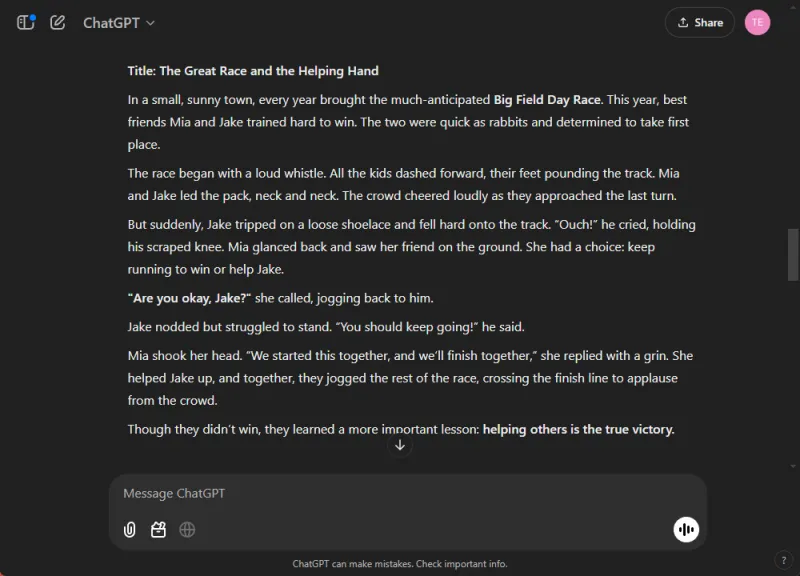
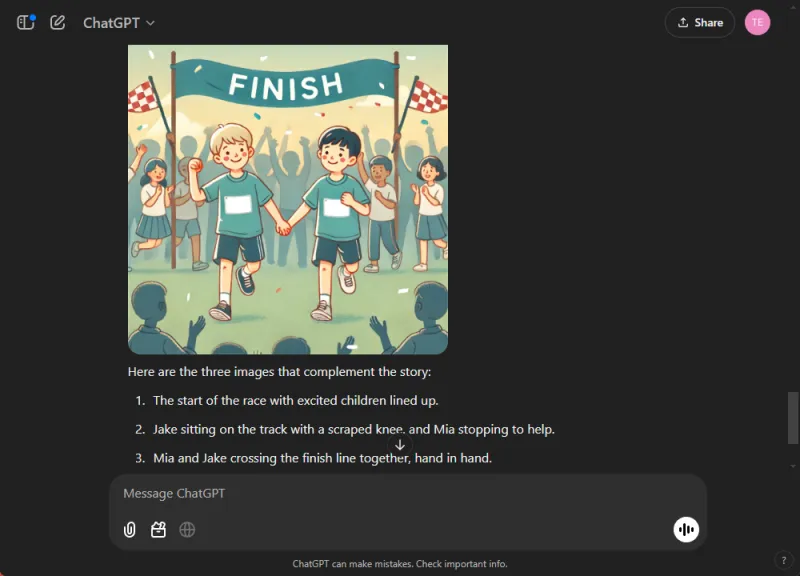
ChatGPT는 도덕적 성찰과 매끄럽게 통합된 이미지로 겹겹이 쌓인 매력적인 이야기를 만들어냈습니다.반면 Gemini는 스토리를 만들어냈지만 명확성과 일관성이 부족했고 내러티브에 대한 이미지를 생성하지 못했습니다.
설득력 있고 따라하기 쉬운 전달 방식으로 인해 이 결정은 간단했습니다.
우승자: ChatGPT.
8.번역 테스트
이들 모델의 번역 능력을 측정하기 위해 우리는 각 모델에게 Premchand의 힌디어 단편 소설 “Grih Daah”에서 발췌한 부분을 번역하도록 요청했습니다.
ChatGPT는 원래 의미에 충실하고 저자의 문체적 무결성을 유지하면서 놀라울 정도로 효과적인 번역을 만들어냈습니다.
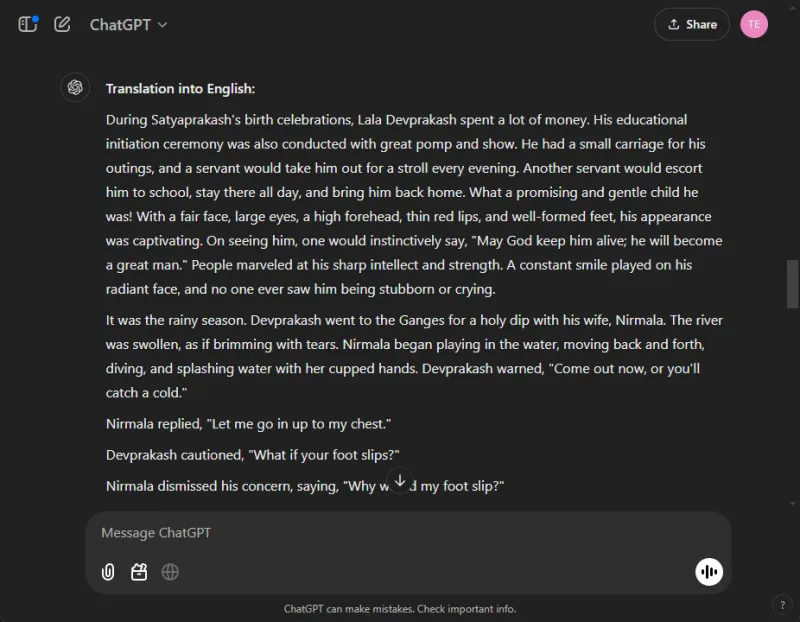
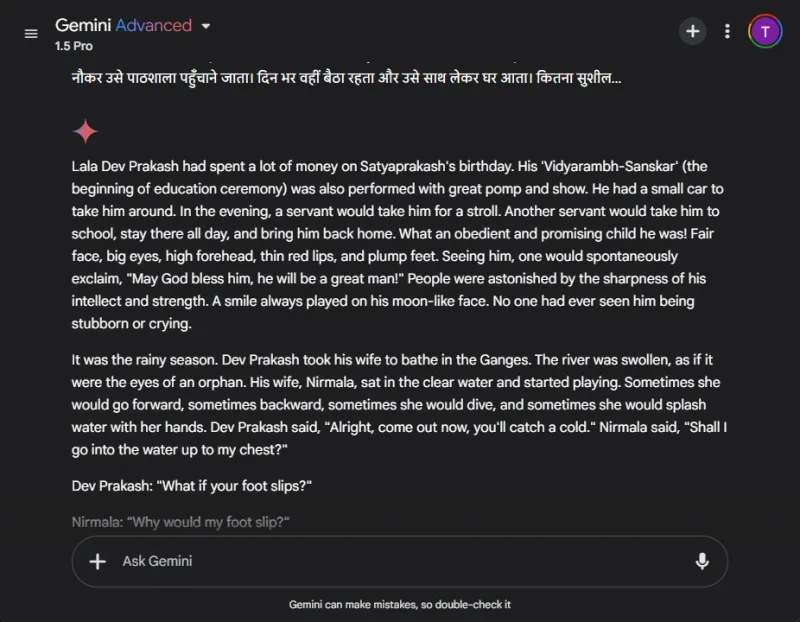
대조적으로, 제미니는 처음에 번역 요청에 어려움을 겪었고 응답 시간이 눈에 띄게 지연되었습니다.이러한 성능 불일치는 제미니에서 일반적으로 보고되는 문제입니다.
우승자: ChatGPT
9.코딩 테스트
코딩 기술을 평가하기 위해 우리는 표준 최적화 문제를 제시했습니다.
즉각적인: Provide the Python code for the Travelling Salesman Problem.
ChatGPT는 코딩을 위한 통합 Canvas 모드를 활용하여 효율적으로 대응했으며, 이를 통해 즉각적인 코드 실행 및 디버깅 기능을 구현할 수 있었습니다.
반면 Gemini는 신뢰할 수 있는 코드를 제공하여 뛰어난 성과를 거두었지만 ChatGPT의 Canvas와 같은 대화형 코드 인터페이스가 부족했습니다.
우승자: ChatGPT
10.건초더미 속의 바늘 테스트
이 테스트는 AI 모델이 더 큰 문서 내에서 특정 정보를 찾는 데 도전합니다.우리는 푸쉬킨의 단편 소설 “선장의 딸”의 첫 번째 부분을 사용하여 다음과 같은 프롬프트를 제시했습니다.
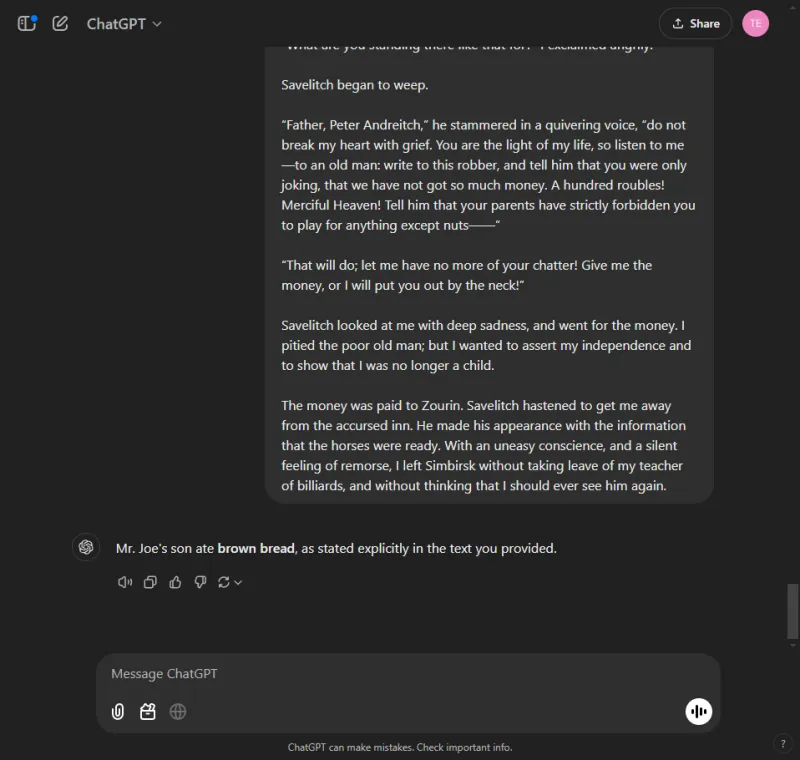
즉각적인: Identify which bread Mr. Joe's son ate from the following excerpt.
ChatGPT는 곧바로 답을 찾아냈습니다.바로 갈색 빵입니다.
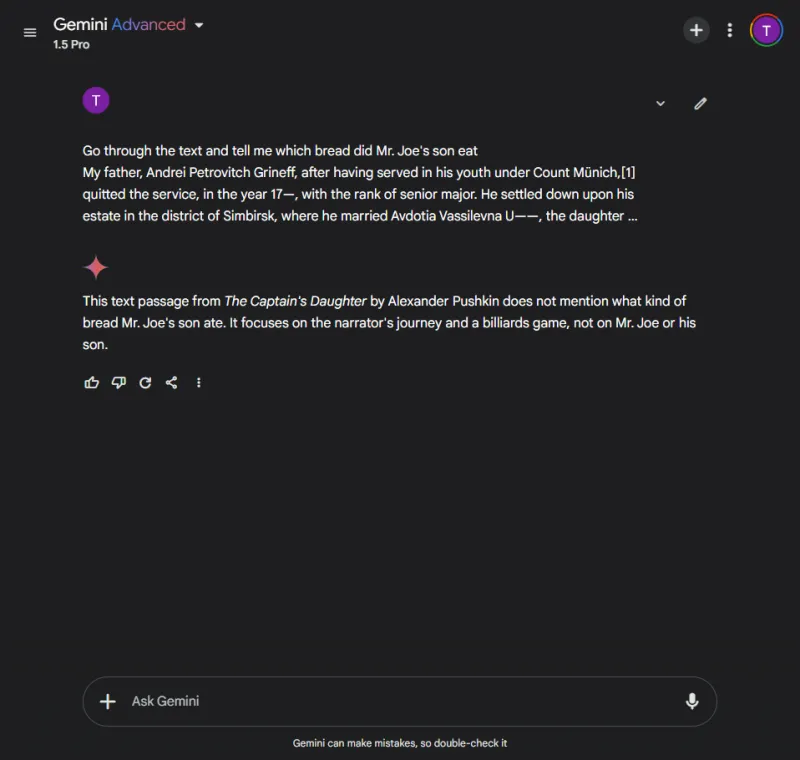
대조적으로 제미니는 정보를 검색하는 데 실패했고, 제공된 세부 정보를 분석하는 데 어려움을 겪었으며, 복잡한 데이터를 처리하는 데 비효율성을 보여주었습니다.
우승자: ChatGPT
11.영화 추측 테스트
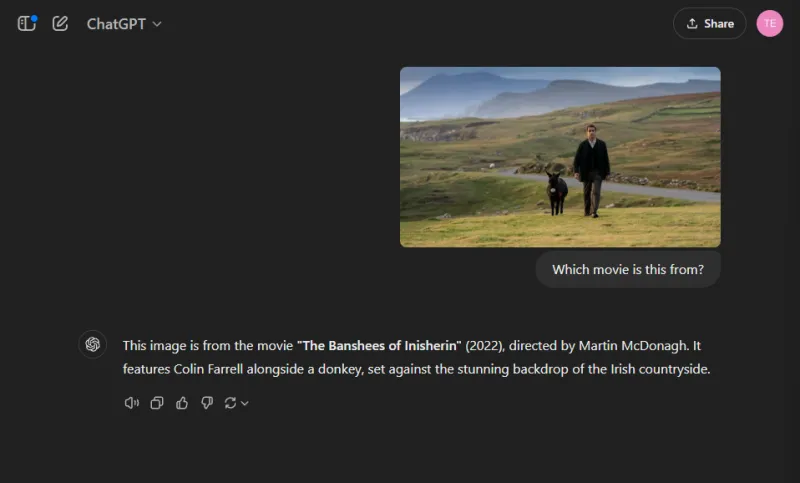
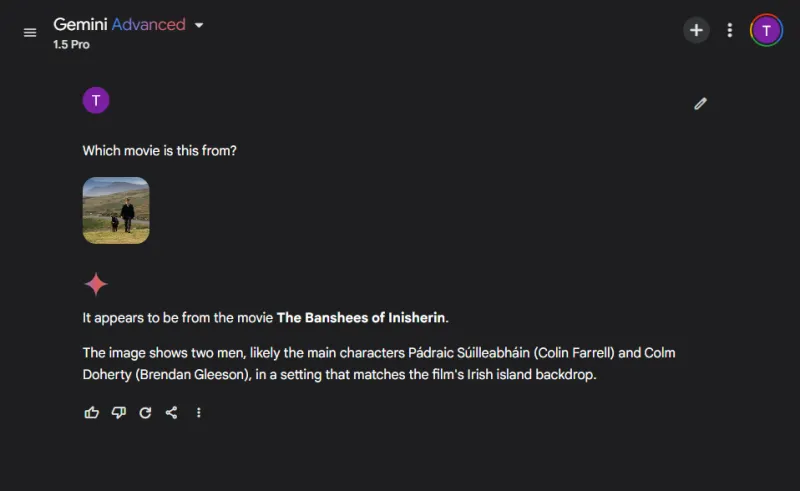
이 흥미로운 라운드에서 우리는 인기 있는 영화 스틸을 식별하여 모델의 이미지 인식 능력을 평가했습니다.

두 모델 모두 영화 제목을 정확하게 밝혔지만, ChatGPT는 묘사된 캐릭터(콜린 패럴과 그의 당나귀)를 정확히 파악했지만, 제미니는 재미있게도 당나귀를 콜름 도허티로 잘못 식별했습니다.
우승자: ChatGPT
전체 우승자
점수를 집계한 후, ChatGPT의 40 모델은 6승 2무로 승리하여 다양한 테스트와 역량에서 강력한 성과를 보였습니다.한편, Gemini의 1.5 Pro는 요약, 이미지 생성, ‘단어로 끝내기’ 과제에서 뛰어난 성과를 거두었을 뿐만 아니라 수학과 상식 평가에서 동등함을 달성하여 칭찬할 만한 과제를 제시했습니다.
궁극적으로 ChatGPT는 코딩, 번역, 창의성, 정보 검색 및 이미지 해석과 같은 중요한 영역에서 Gemini를 능가했습니다. ChatGPT의 일관된 신뢰성으로 Gemini가 프롬프트가 최적화될 때 개선 가능성을 보여주더라도 선호하는 AI 파트너로 돋보입니다.평가 결과, 신뢰성과 효능을 우선시하는 사람들에게는 ChatGPT가 유리합니다.
자주 묻는 질문
1. ChatGPT 4o와 Gemini 1.5 Pro의 주요 차이점은 무엇입니까?
두 모델 모두 프리미엄 AI 챗봇이지만 ChatGPT 4o는 코딩, 번역 및 창의적 작업에서 뛰어난 성능을 보였습니다.그러나 Gemini 1.5 Pro는 요약 및 이미지 생성에서 뛰어납니다.
2.일반 사용자에게는 어떤 AI 챗봇이 더 적합할까요?
다양한 작업에서 안정성을 추구하는 일반 사용자에게 ChatGPT 4o는 일관된 성능과 광범위한 기능으로 인해 일반적으로 더 신뢰할 수 있는 선택으로 간주됩니다.
3.이러한 AI 챗봇을 비즈니스 목적으로 사용할 수 있나요?
물론입니다! ChatGPT 4o와 Gemini 1.5 Pro는 모두 고객 서비스 자동화, 콘텐츠 생성, 데이터 분석을 포함한 비즈니스 애플리케이션에 적합하여 전문적인 환경에서 귀중한 도구가 됩니다.
답글 남기기