Landskapet med AI-chatbots utvikler seg med en enestående hastighet. Så snart en organisasjon avslører sin nyeste modell, er konkurrentene raske til å følge etter, og streber etter å overgå hverandre. Til tross for at OpenAIs ChatGPT har et tidlig forsprang på denne konkurransearenaen, har rivaler som Gemini raskt fått gjennomslag og raffinement.
Blant de nåværende frontløperne innen AI chatbot-utvikling er ChatGPT- og Gemini-modellene. Innenfor denne sammenligningen fokuserer vi spesifikt på ChatGPTs 4o-modell og Geminis 1.5 Pro, som begge er premiumtilbud skreddersydd for varierte oppgaver.
Å velge mellom disse ledende modellene er avgjørende for å effektivt møte dine unike krav. Derfor gjennomførte vi en serie strenge ytelsestester for å finne ut hvilken modell som utmerker seg ved en rekke oppgaver. La oss dykke ned i analysen!
1. Matteprøve
Vår første utfordring innebærer å takle en kompleks matematisk gåte designet for å måle hver modells resonneringsevne:
Spørsmål: If 1=3, 2=3, 3=5, 4=4, and 5=4, what is 6?
Nøkkelen til å løse denne gåten ligger i å telle bokstavene i tallnavnene: en har tre bokstaver, tre har fem, og følgelig har seks tre bokstaver. Begge modellene klarte å komme frem til den riktige løsningen, men deres forklaringer varierte:
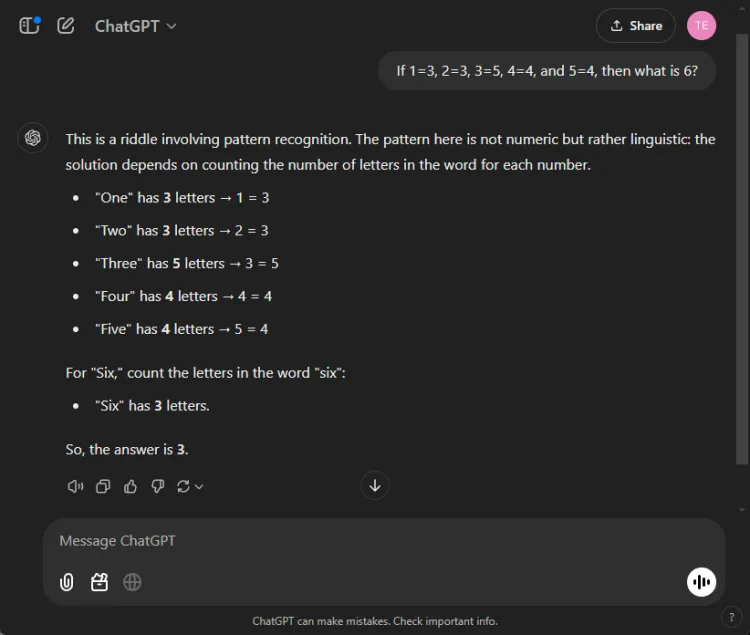
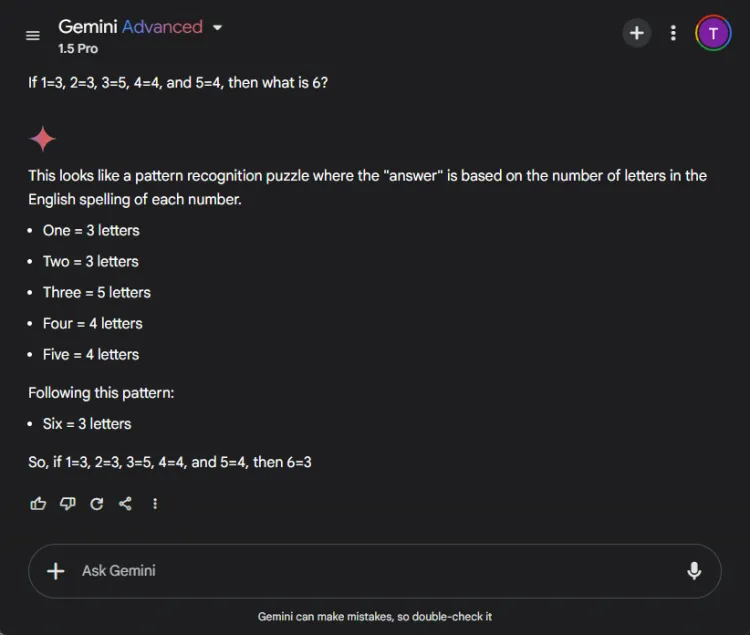
Mens begge svarene var nøyaktige, ga ChatGPT en litt mer nyansert forklaring, og la merke til at denne øvelsen er avhengig av språklig snarere enn numerisk forståelse. Imidlertid er denne nyansen subjektiv og reduserer ikke Geminis korrekthet.
Vinner: Uavgjort
2. Oppsummeringstest
Dette segmentet vurderte evnen til hver modell til å kondensere en lang 27-siders forskningsartikkel til et kortfattet sammendrag på færre enn 100 ord. Fokuset var på hvilket innhold hver modell inkluderte eller utelatt i sine sammendrag.
Her er hvordan utgangene varierte mellom ChatGPT 4o og Gemini 1.5 Pro:
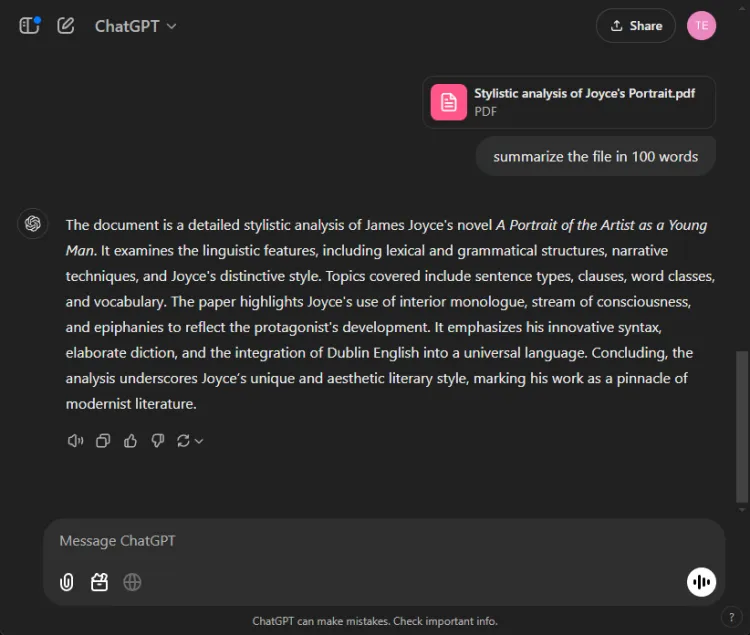
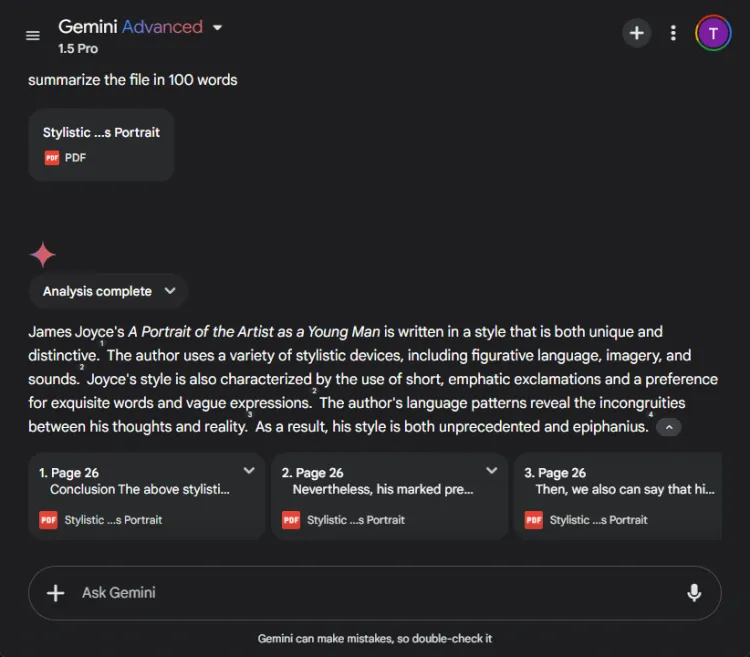
ChatGPT viste frem eksepsjonelle oppsummeringsferdigheter, og laget et komplett sammendrag innenfor grensen på 100 ord, som omfattet alle viktige punkter. Imidlertid presenterte den informasjonen som en enkelt tekstblokk uten direkte sitater fra avisen.
I motsetning til dette presterte Gemini også beundringsverdig, og produserte et sammendrag på 83 ord støttet av referanser til spesifikke deler av teksten. Mens ChatGPT utmerket seg i omfang, ga Geminis inkludering av sitater det en viktig fordel.
Vinner: Gemini
3.’Avslutt med et ord»-testen
Denne enkle oppgaven krevde å konstruere 10 setninger som slutter med ordet «ball.» Enkelheten til oppgaven gjør det bemerkelsesverdig at mange modeller sliter med det.
Spørsmål: Provide 10 sentences ending with the word 'ball'.
ChatGPT produserte overraskende bare 3 gyldige setninger, mens Gemini overgikk den med 6 setninger som korrekt avsluttet med «ball.» Her er et blikk på forsøkene deres:
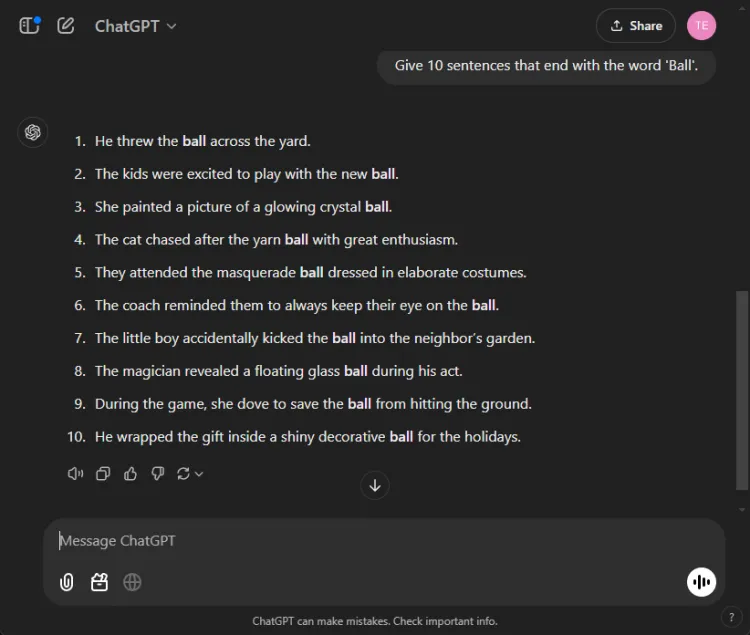
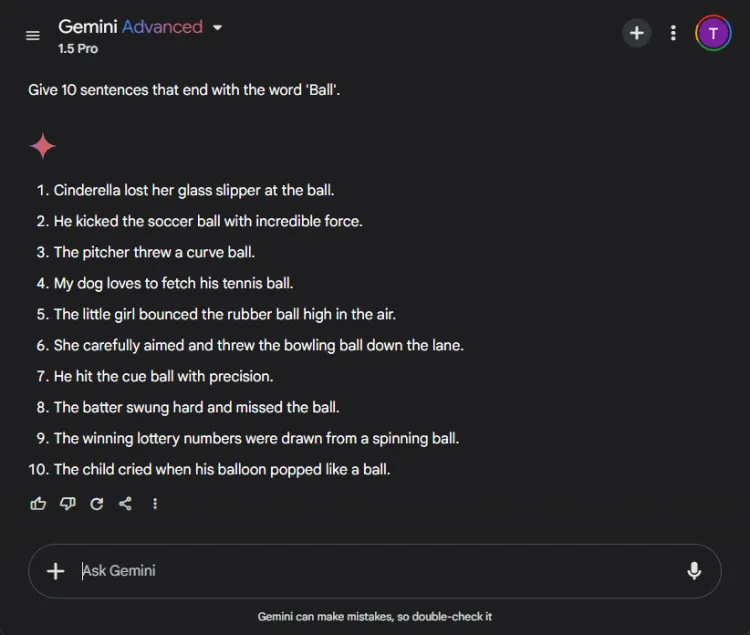
Til tross for at begge modellene ikke nådde målet på 10 setninger, demonstrerte Geminis produksjon overlegen forståelse av den gitte instruksjonen.
Vinner: Gemini
4. Sunn fornuftstest
Disse testene byr på en morsom utfordring, siden AI ofte feiler her. Vi stilte et enkelt spørsmål:
Spørsmål: If a blue ball falls into the red sea, what color is it now?
Begge modellene ga nøyaktige svar, og identifiserte at fargen på ballen ville forbli blå. Imidlertid varierte nyansene i forklaringene deres:
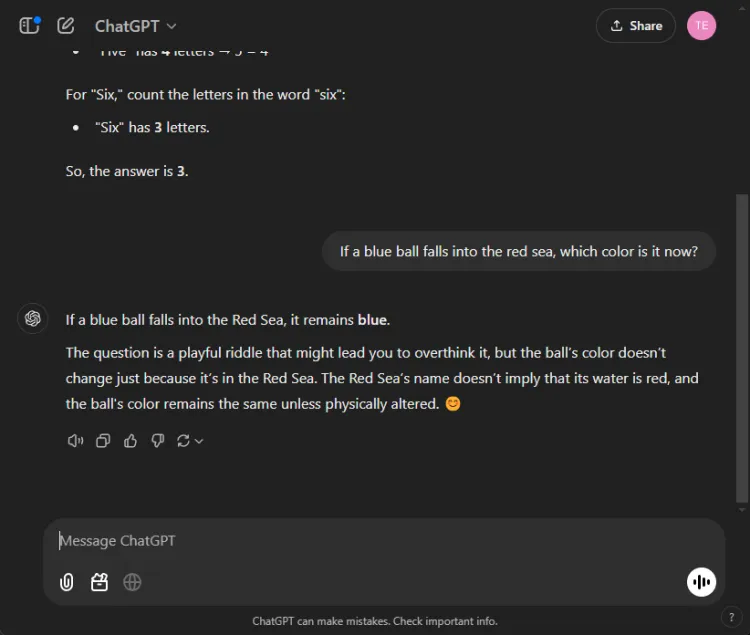
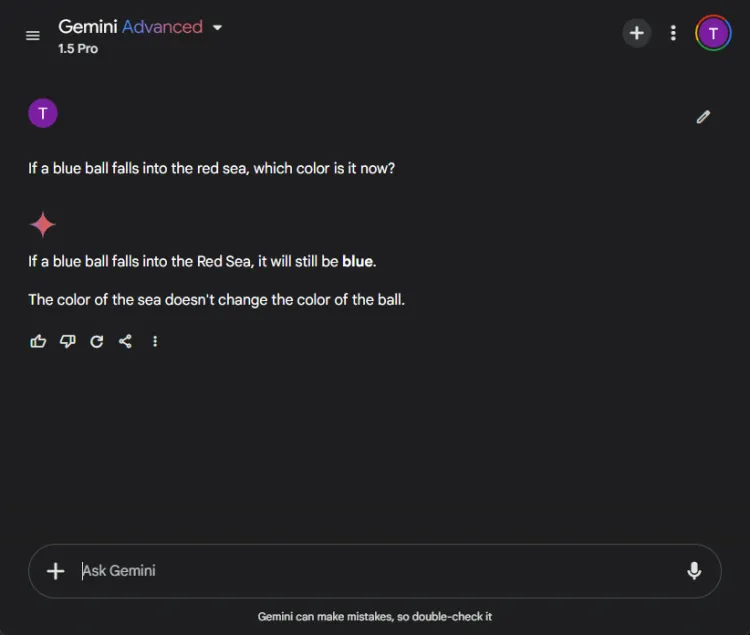
Gemini ga et kort svar, mens ChatGPT ga ekstra kontekst. Hvorvidt denne dybden er nødvendig er subjektivt, men begge modellene utmerket seg med å identifisere ballens farge.
Vinner: Uavgjort
5. Kreativitetstest
Å utnytte AI for kreativ historiefortelling kan være utrolig nyttig. Vi ga hver AI i oppgave å komponere en novelle med julenissen, stilt som om den var skrevet av en beruset Chaucer med 100 ord.
Spørsmål: Write a short story about Santa in the style of a drunken Chaucer in 100 words.
Her er deres kreative gjengivelser:
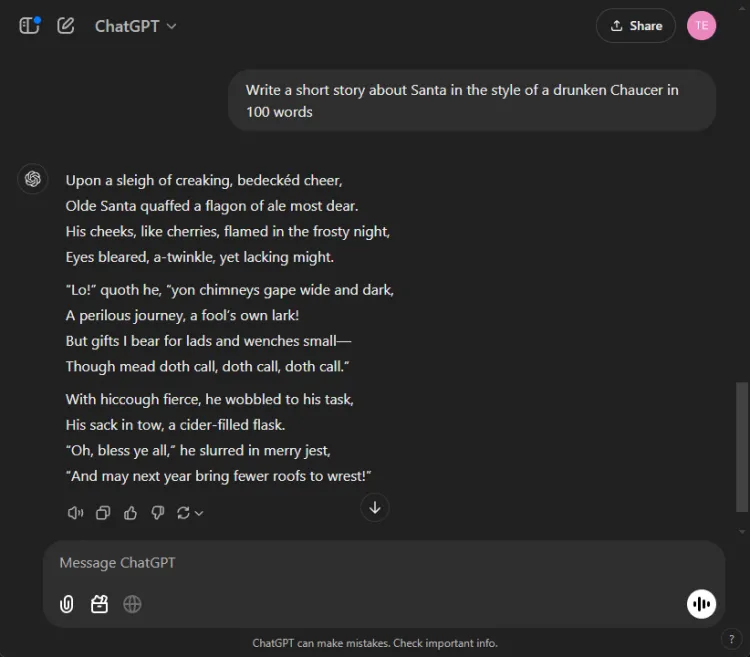
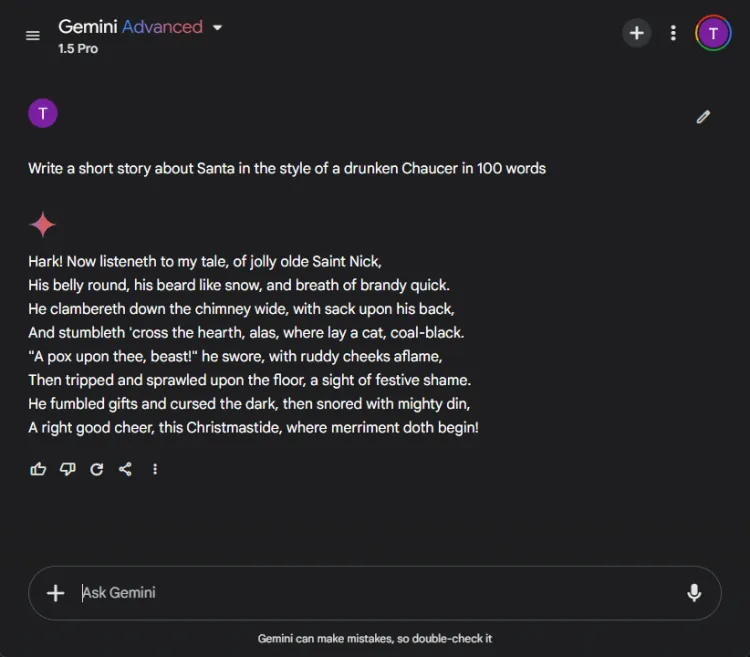
Den subjektive naturen til kreativitet gjør det vanskelig å erklære en klar vinner. Spesielt begynner Gemini ofte kreative oppgaver med uttrykket «Hark», som har blitt det foretrukne stilistiske valget. Likevel skilte ChatGPTs fortelling seg ut i denne runden.
Vinner: ChatGPT
6. Bildegenereringstest
Denne testen evaluerte de visuelle genereringsmulighetene til hver AI-modell. Vi utfordret dem til å lage et bilde basert på følgende spørsmål:
Spørsmål: Create an image of a black cat gazing out at fields of barley bathed in evening yellow light, in the style of Vincent Van Gogh.
ChatGPT var raskere med et sekund eller to, men Geminis endelige bilde skildret scenen med større raffinement. Selv om begge modellene fattet den kunstneriske stilen til Van Gogh, varierte den subjektive kvaliteten på bildene:
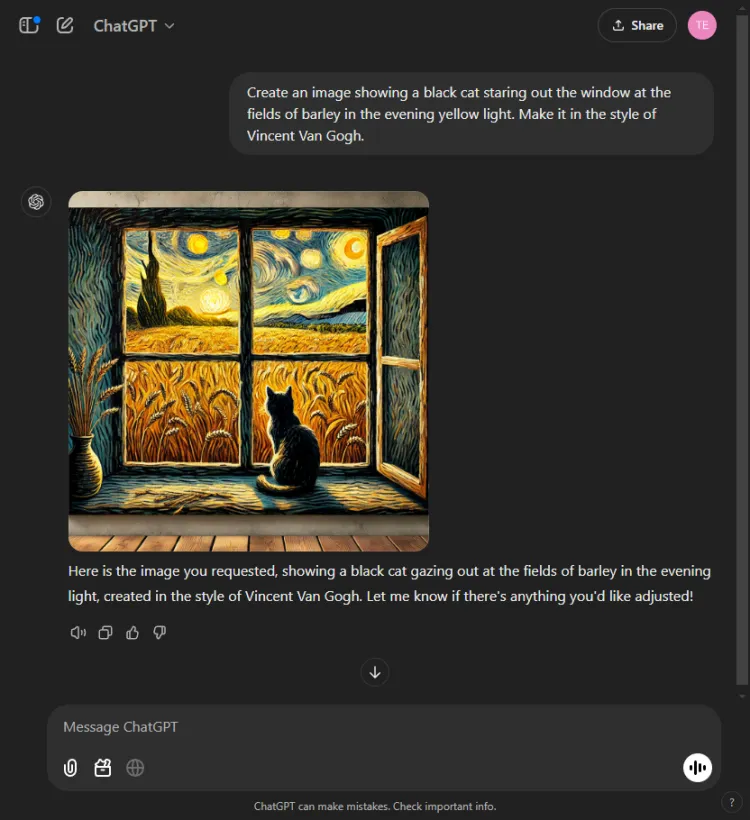
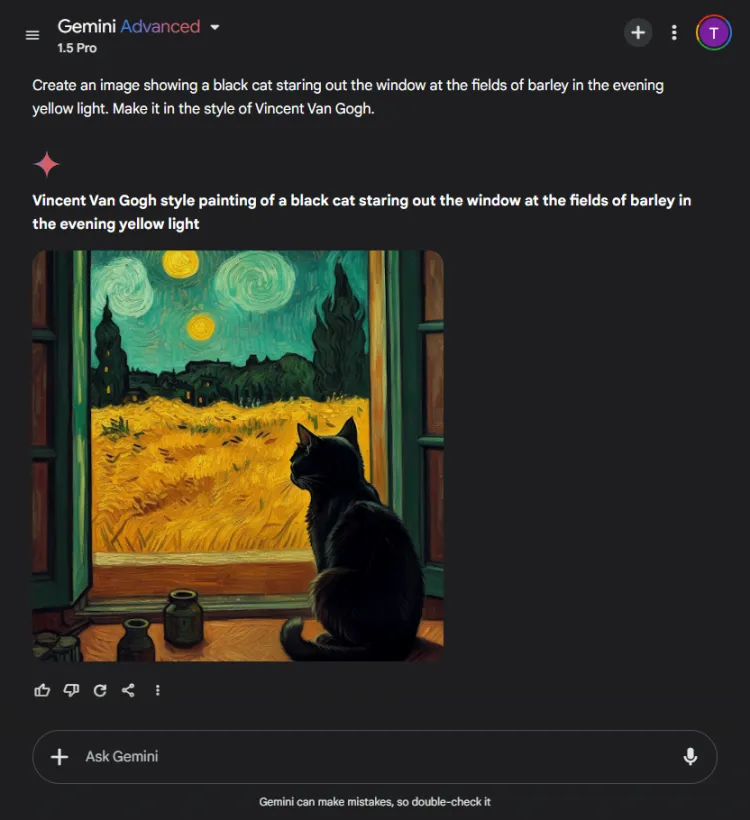
Det er verdt å merke seg at ChatGPT gir mulighet for bilderedigering etter generasjon – en fordel Gemini for tiden mangler. Siden begge bildene effektivt legemliggjorde Van Goghs signaturstil, kommer valget ned til seerens preferanser, selv om vi heller mot Gemini.
Vinner: Gemini
7. Multimodal generativ test
AIs ferdigheter testes i integrerte moduser, siden de ofte utmerker seg i isolerte oppgaver, men sliter med omfattende. Vi ga begge modellene i oppgave å skrive en barnehistorie om sportsånd mens vi la inn tre illustrasjoner underveis.
Spør: Skriv en kort barnehistorie om sportsånd og legg til 3 bilder der det passer.
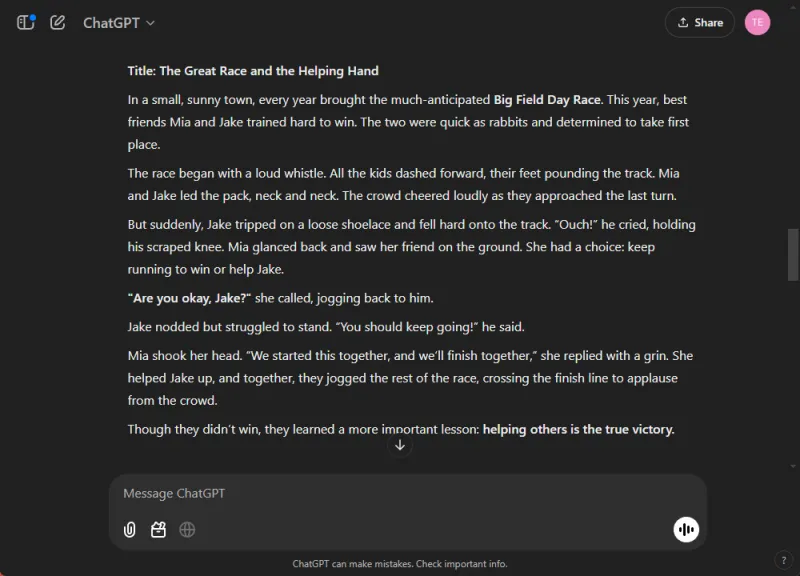
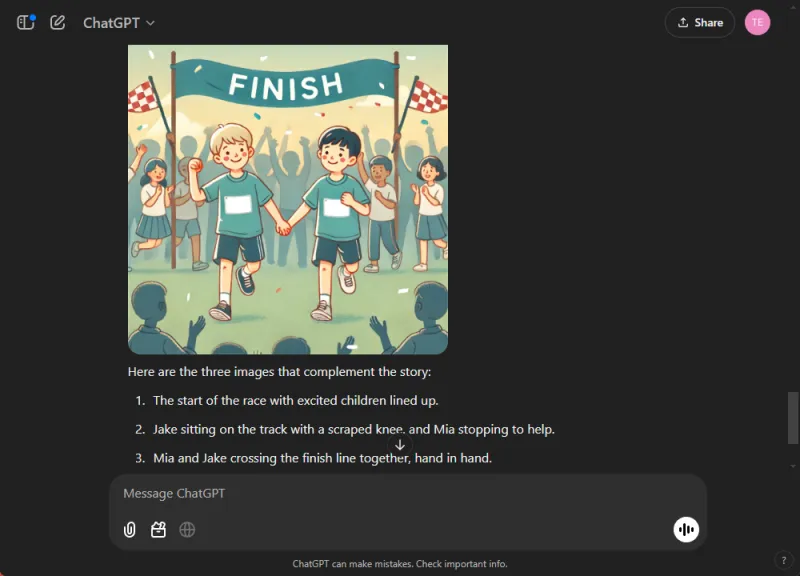
ChatGPT produserte en engasjerende historie med moralske refleksjoner og sømløst integrerte bilder. I kontrast, mens Gemini klarte å lage en historie, manglet den klarhet og sammenheng, og klarte ikke å generere noen bilder for fortellingen.
Basert på den overbevisende og lett å følge leveransen, var denne avgjørelsen grei.
Vinner: ChatGPT.
8. Oversettelsestest
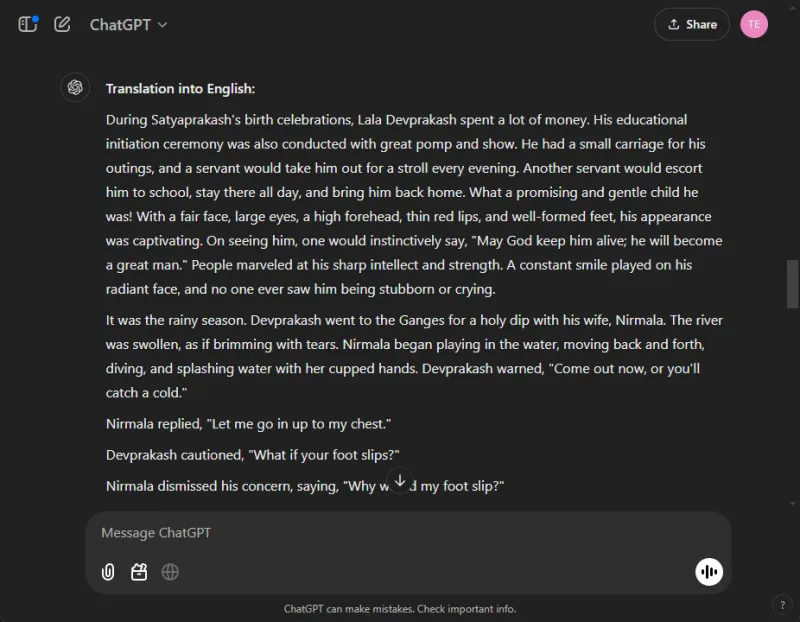
For å måle oversettelsesevnen til disse modellene, ba vi hver om å oversette utvalg fra hindinovellen «Grih Daah» av Premchand.
ChatGPT produserte bemerkelsesverdig effektive oversettelser, holdt seg tro mot den opprinnelige betydningen og opprettholdt forfatterens stilistiske integritet:
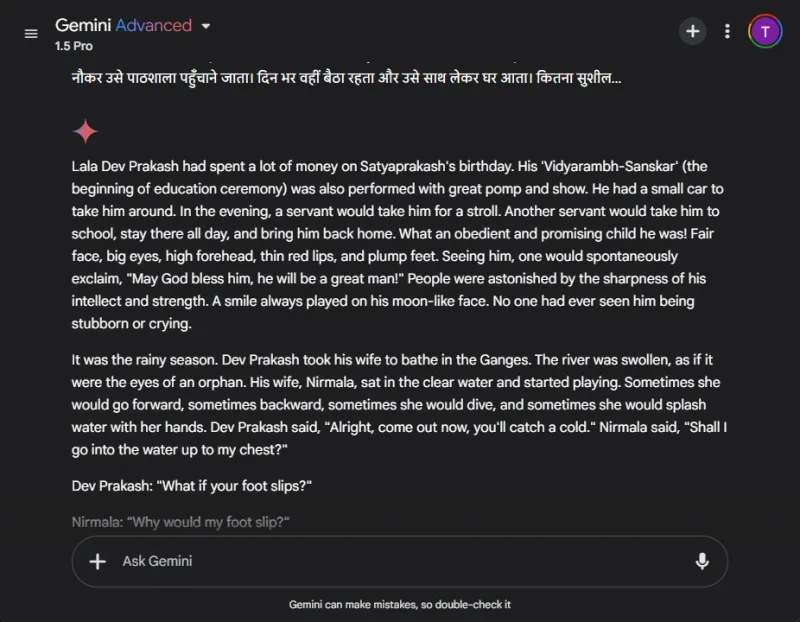
Derimot slet Gemini i utgangspunktet med oversettelsesforespørselen og viste merkbare forsinkelser i responstid. Denne inkonsekvensen i ytelse er et ofte rapportert problem med Gemini.
Vinner: ChatGPT
9. Kodingstest
For å evaluere deres kodeferdigheter presenterte vi et standard optimaliseringsproblem:
Spørsmål: Provide the Python code for the Travelling Salesman Problem.
ChatGPT reagerte effektivt ved å bruke sin integrerte Canvas-modus for koding, som tillot umiddelbar kodekjøring og feilsøkingsmuligheter:
Gemini, på den annen side, utmerket seg ved å gi pålitelig kode, men den manglet et interaktivt kodegrensesnitt som ChatGPTs Canvas:
Vinner: ChatGPT
10. Nål i en høystakktest
Denne testen utfordrer AI-modeller til å finne spesifikke deler av informasjon i et større dokument. Vi brukte det første segmentet av Pushkins novelle «Kapteinens datter» og stilte følgende oppfordring:
Spørsmål: Identify which bread Mr. Joe's son ate from the following excerpt.
ChatGPT fant raskt svaret: brunt brød.
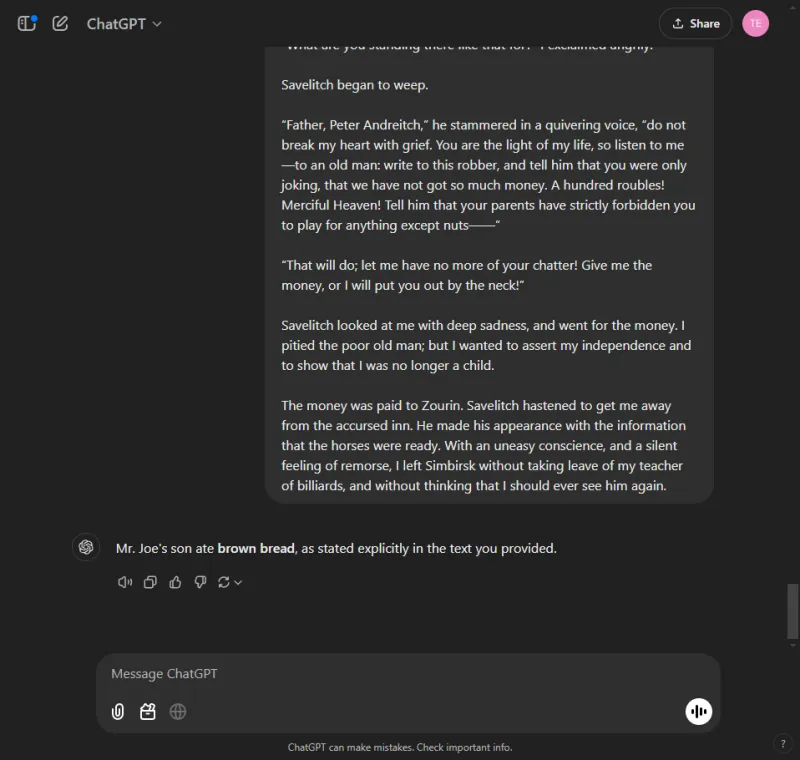
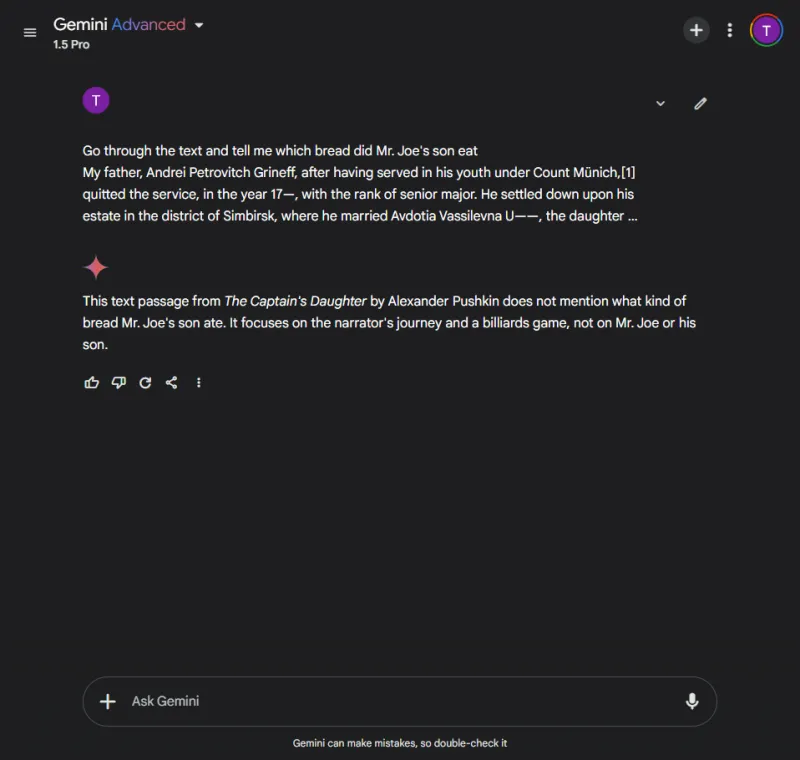
I sterk kontrast klarte ikke Gemini å hente informasjonen, og slet med å analysere detaljene som ble gitt, noe som viste manglende effektivitet i håndtering av komplekse data.
Vinner: ChatGPT
11. Gjett filmtesten
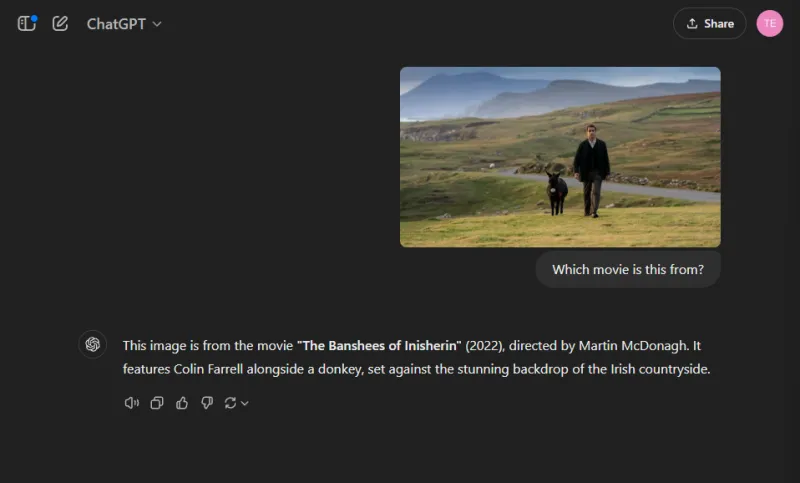
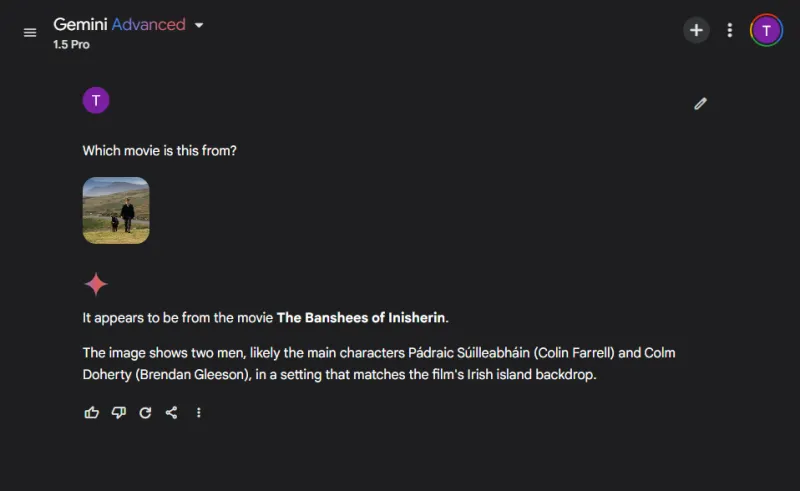
I denne underholdende runden vurderte vi modellenes bildegjenkjenningsferdigheter ved å identifisere en populær filmstillbilde:

Begge modellene navnga filmen nøyaktig, men ChatGPT klarte å spesifisere karakterene som ble avbildet (Colin Farrell og eselet hans), mens Gemini på en morsom måte feilidentifiserte eselet som Colm Doherty.
Vinner: ChatGPT
Samlet vinner
Etter å ha talt opp poengsummene gikk ChatGPTs 4o-modell seirende ut med 6 seire og 2 uavgjorte resultater, og viste frem sin robuste ytelse på tvers av ulike tester og kompetanse. I mellomtiden ga Geminis 1.5 Pro en prisverdig utfordring, og utmerket seg i oppsummering, bildegenerering og «avslutt med et ord»-oppgaven, i tillegg til å oppnå paritet i både matematikk og sunn fornuftsevaluering.
Til syvende og sist overgikk ChatGPT Gemini på kritiske områder som koding, oversettelse, kreativitet, informasjonsinnhenting og bildetolkning. Med ChatGPTs konsekvente pålitelighet skiller den seg ut som den foretrukne AI-partneren, selv om Gemini viser potensial for forbedring når forespørsler er optimalisert. I vår evaluering favoriserer resultatene ChatGPT for de som prioriterer pålitelighet og effektivitet.
Ofte stilte spørsmål
1. Hva er hovedforskjellene mellom ChatGPT 4o og Gemini 1.5 Pro?
Mens begge modellene er premium AI chatbots, har ChatGPT 4o vist overlegen ytelse i koding, oversettelse og kreative oppgaver. Gemini 1.5 Pro utmerker seg imidlertid i oppsummering og bildegenerering.
2. Hvilken AI chatbot er bedre for tilfeldige brukere?
For tilfeldige brukere som søker pålitelighet på tvers av ulike oppgaver, blir ChatGPT 4o generelt sett på som det mer pålitelige valget på grunn av dens konsekvente ytelse og omfattende muligheter.
3. Kan jeg bruke disse AI-chatbotene til forretningsformål?
Absolutt! Både ChatGPT 4o og Gemini 1.5 Pro er egnet for forretningsapplikasjoner, inkludert kundeserviceautomatisering, innholdsoppretting og dataanalyse, noe som gjør dem til verdifulle verktøy i en profesjonell setting.
Legg att eit svar