人工智慧聊天機器人的前景正以前所未有的速度發展。一旦組織推出最新模型,競爭對手就會迅速效仿,力爭超越對方。儘管 OpenAI 的 ChatGPT 在這一競爭舞台上享有早期領先地位,但像 Gemini 這樣的競爭對手卻迅速獲得了關注和成熟度。
目前人工智慧聊天機器人開發的領跑者包括 ChatGPT 和 Gemini 模型。在這次比較中,我們特別關注 ChatGPT 的 4o 型號和 Gemini 的 1.5 Pro,這兩者都是針對不同任務量身定制的優質產品。
在這些領先型號之間進行選擇對於有效滿足您的獨特需求至關重要。因此,我們進行了一系列嚴格的效能測試,以確定哪種模型在多種任務上表現出色。下面我們就來深入分析一下吧!
1.數學測試
我們的第一個挑戰涉及解決一個複雜的數學謎題,旨在衡量每個模型的推理能力:
迅速的: If 1=3, 2=3, 3=5, 4=4, and 5=4, what is 6?
解開這個謎題的關鍵在於數數字名稱中的字母:一有三個字母,三有五個字母,因此六有三個字母。兩種模型都設法得出正確的解決方案,但它們的解釋有所不同:
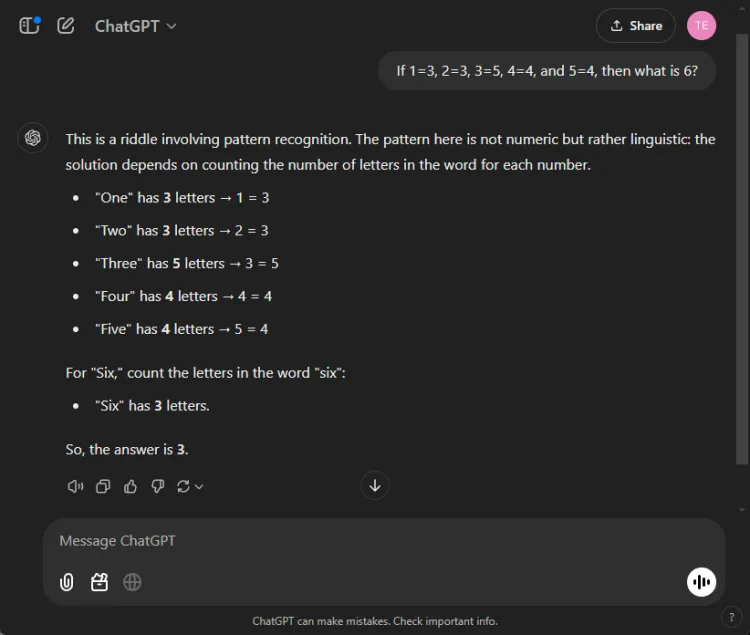
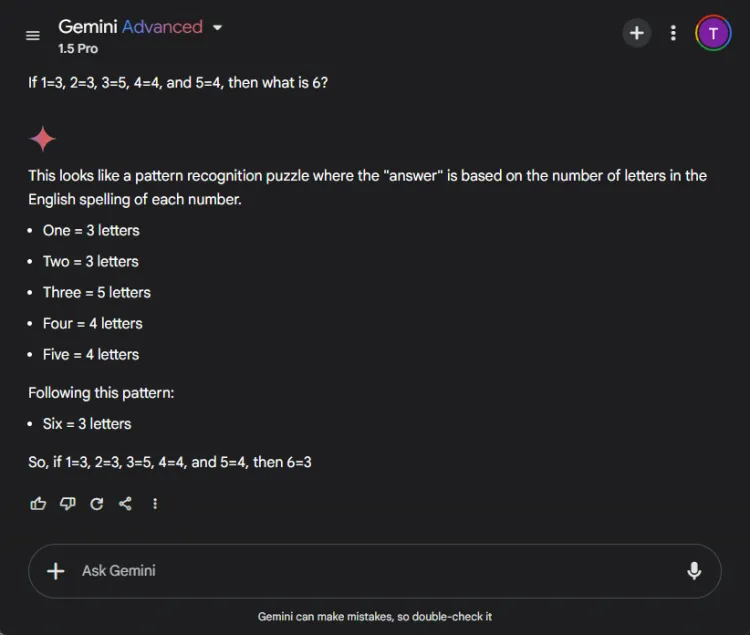
雖然這兩種回答都是準確的,但 ChatGPT 提供了稍微更細緻的解釋,指出此練習依賴語言理解而不是數字理解。然而,這種細微差別是主觀的,並不會削弱雙子座的正確性。
獲勝者: 平局
2.總結測試
該部分評估了每個模型將 27 頁長的研究論文壓縮為少於 100 個單字的簡潔摘要的能力。重點是每個模型在摘要中包含或省略了哪些內容。
以下是 ChatGPT 4o 和 Gemini 1.5 Pro 之間的輸出差異:
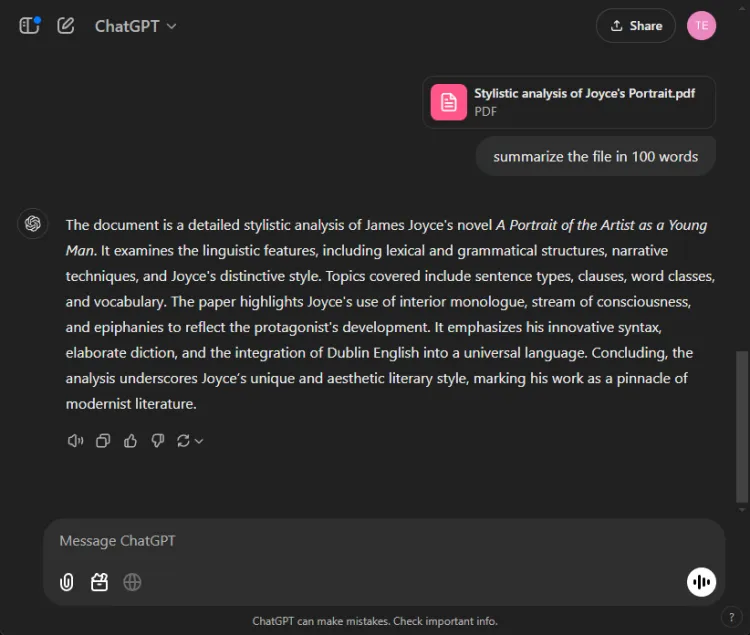
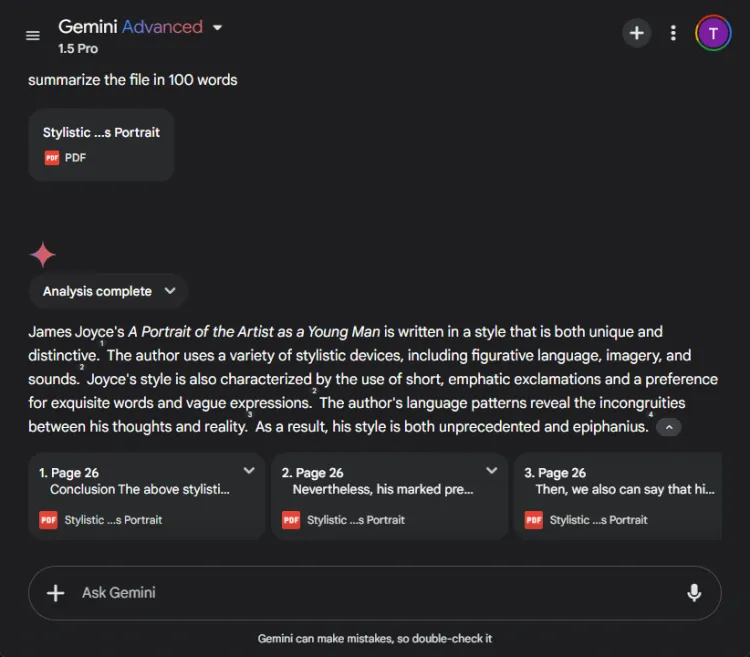
ChatGPT 展示了出色的摘要技巧,在 100 字的限制內製作了完整的摘要,涵蓋了所有要點。然而,它以單一文本區塊的形式呈現訊息,而沒有直接引用論文。
相比之下,Gemini 也表現出色,產生了 83 字的摘要,並引用了文本的特定部分。雖然 ChatGPT 在全面性方面表現出色,但 Gemini 的引用為其提供了重要優勢。
獲勝者: 雙子座
3.「以一句話結束」測試
這項簡單的任務需要建構 10 個以「球」一詞結尾的句子。
迅速的: Provide 10 sentences ending with the word 'ball'.
令人驚訝的是,ChatGPT 只產生了 3 個有效句子,而 Gemini 則以 6 個正確以“ball”結尾的句子超越了它。
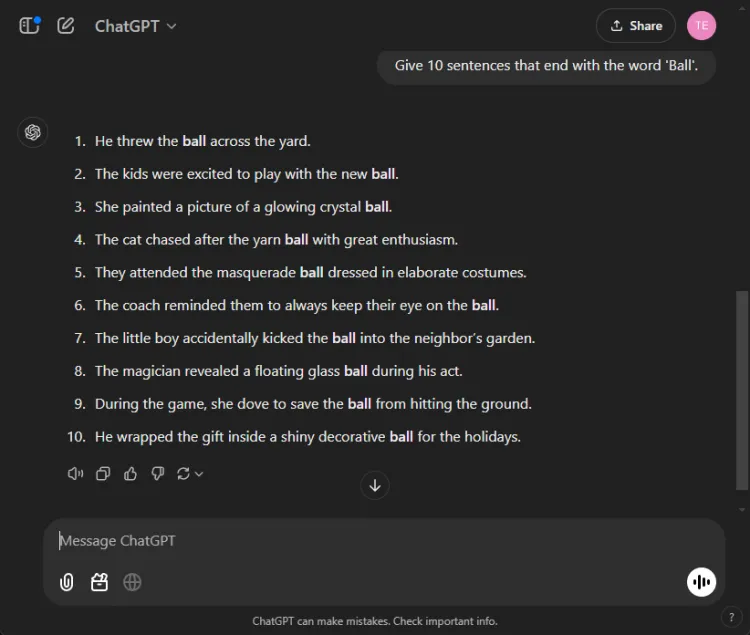
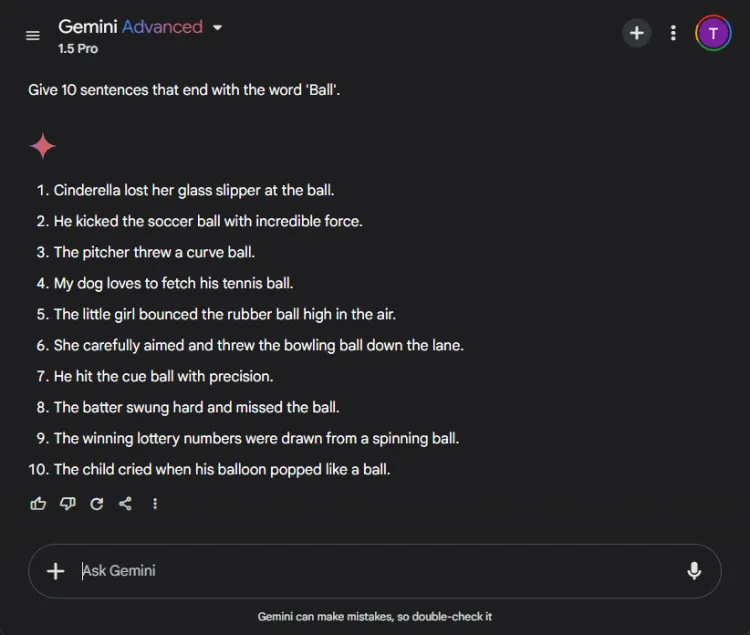
儘管兩個模型都沒有達到 10 句話的目標,但 Gemini 的輸出顯示出對給定指令的出色掌握。
獲勝者: 雙子座
4.常識測試
這些測試提出了一個有趣的挑戰,因為人工智慧經常在這方面犯錯。我們提出了一個簡單的問題:
迅速的: If a blue ball falls into the red sea, what color is it now?
兩個模型都給出了準確的答案,確定球的顏色將保持藍色。然而,他們的解釋存在細微差別:
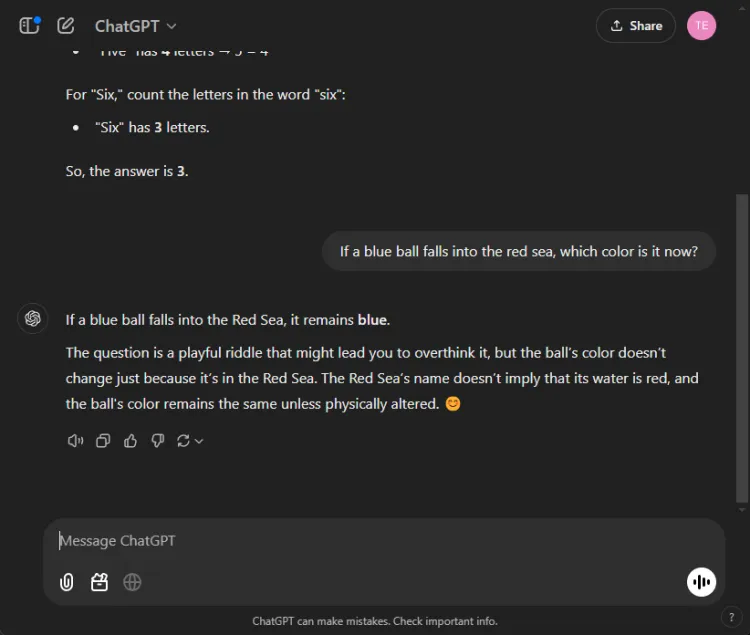
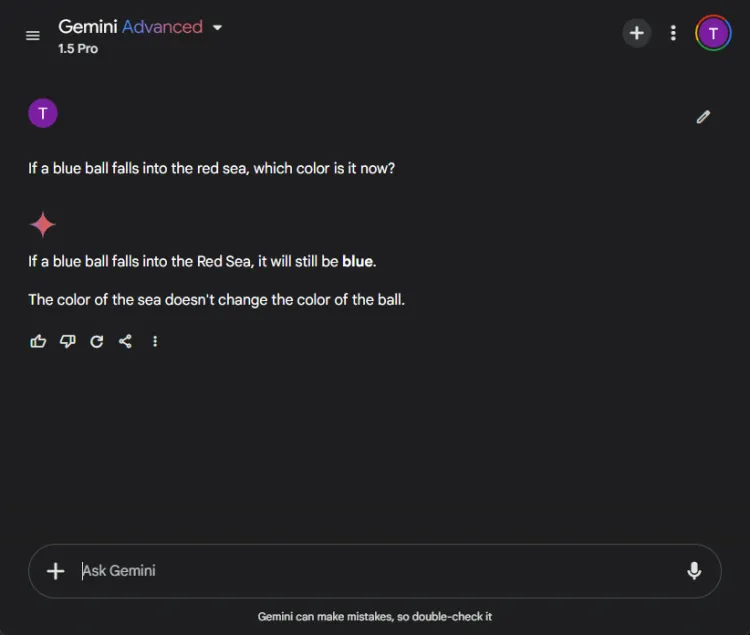
Gemini 提供了簡短的回應,而 ChatGPT 則提供了更多背景資訊。這種深度是否必要是主觀的,但兩種模型都擅長辨識球的顏色。
獲勝者: 平局
5.創造力測試
利用人工智慧進行創意的故事講述會非常有幫助。我們要求每個人工智慧撰寫一個以聖誕老人為主角的短篇故事,其風格就像喝醉了的喬叟用 100 字寫的一樣。
迅速的: Write a short story about Santa in the style of a drunken Chaucer in 100 words.
以下是他們的創意效果圖:
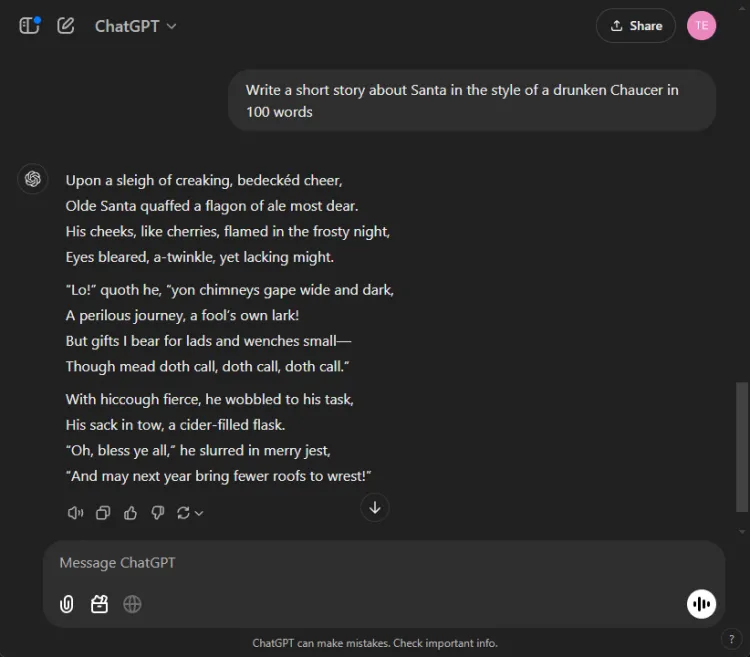
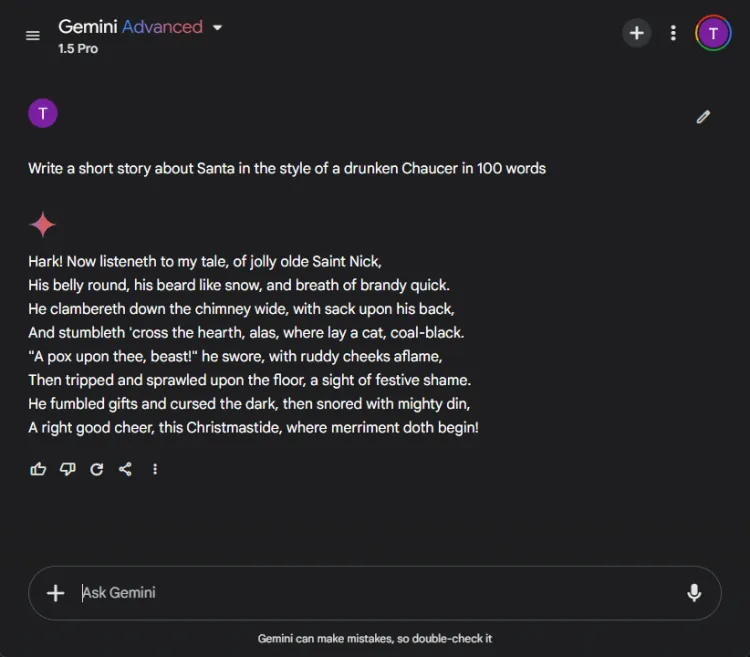
創造力的主觀性使得很難宣布誰是明顯的贏家。值得注意的是,雙子座經常以“Hark”這個短語開始創造性任務,這已成為其首選的風格選擇。儘管如此,ChatGPT 的敘述在這一輪中脫穎而出。
獲勝者: ChatGPT
6.影像生成測試
該測試評估了每個人工智慧模型的視覺生成能力。我們要求他們根據以下提示創建圖像:
迅速的: Create an image of a black cat gazing out at fields of barley bathed in evening yellow light, in the style of Vincent Van Gogh.
ChatGPT 快了一兩秒,但 Gemini 的最終圖像以更複雜的方式描繪了場景。儘管兩位模特兒都掌握了梵高的藝術風格,但影像的主觀品質有所不同:
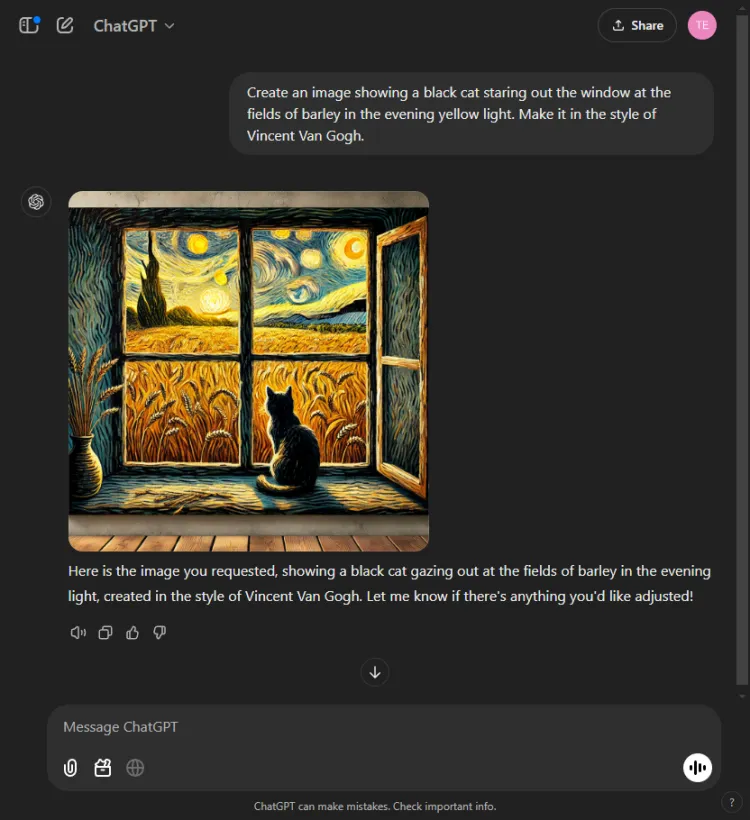
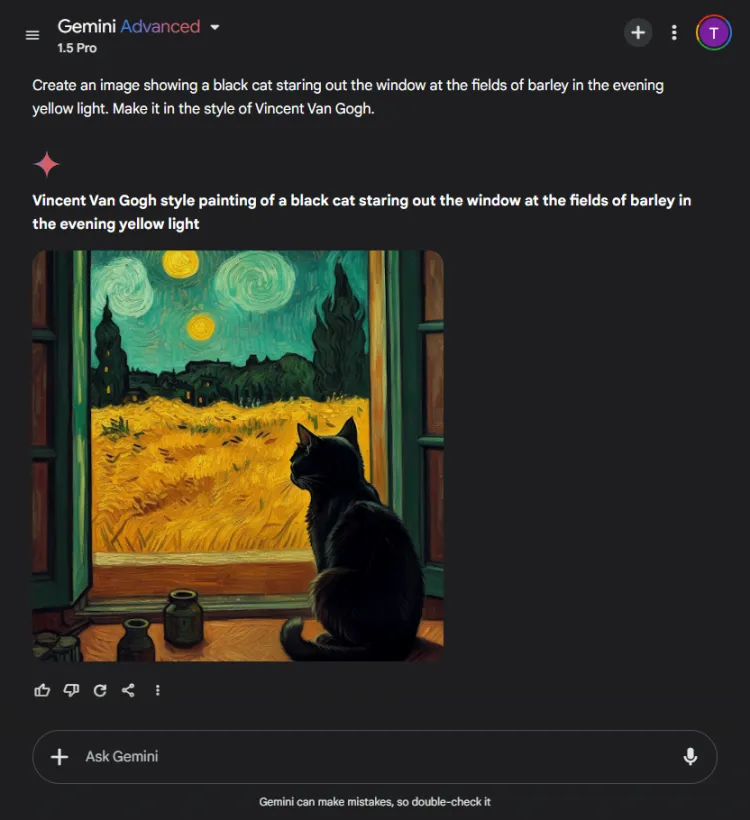
值得注意的是,ChatGPT 允許在生成後進行影像編輯——這是 Gemini 目前所缺乏的優勢。由於這兩張圖片都有效地反映了梵谷的標誌性風格,因此選擇取決於觀眾的喜好,儘管我們傾向於雙子座。
獲勝者: 雙子座
7.多模態生成測試
人工智慧的熟練程度是在整合模式下進行測試的,因為它們通常在孤立的任務中表現出色,但在綜合任務中卻表現不佳。我們要求兩位模特兒寫一個關於運動精神的兒童故事,同時插入三個插圖。
提示:寫一個關於體育精神的簡短兒童故事,並在適當的情況下添加 3 張圖片。
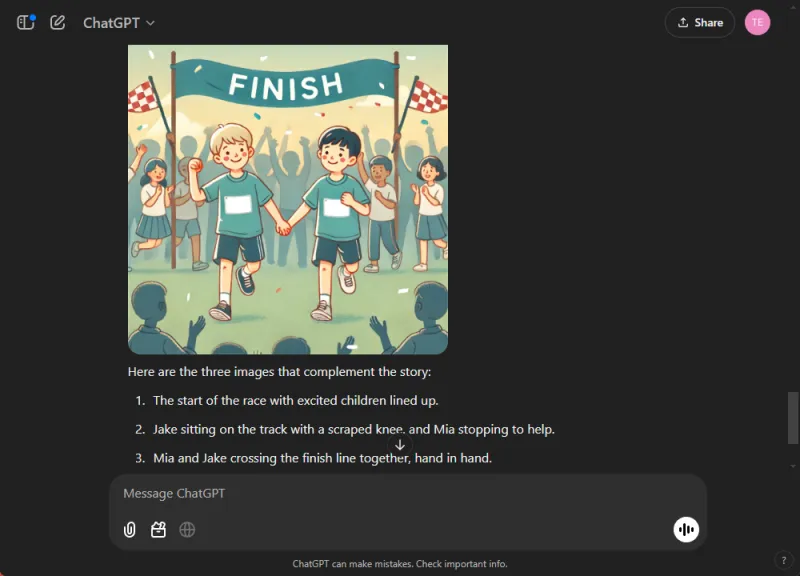
ChatGPT 製作了一個引人入勝的故事,其中充滿了道德反思和無縫融合的圖像。相較之下,雙子座雖然成功地創造了一個故事,但缺乏清晰度和連貫性,並且未能為敘事生成任何圖像。
基於引人注目且易於遵循的交付,這個決定很簡單。
獲勝者: ChatGPT。
8.翻譯測試
為了衡量這些模型的翻譯能力,我們要求每個模型翻譯 Premchand 的印地語短篇小說“Grih Daah”中的選集。
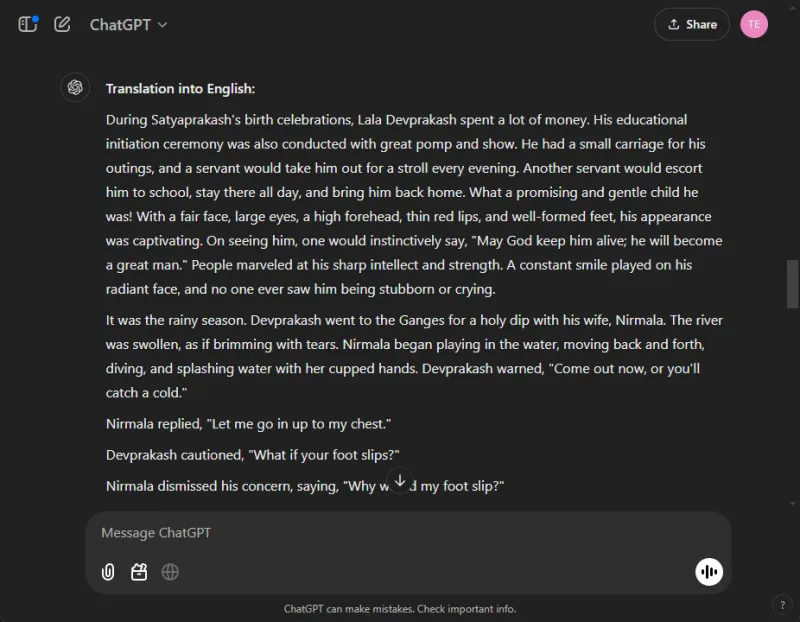
ChatGPT 產生了非常有效的翻譯,忠於原文意義並保持了作者風格的完整性:
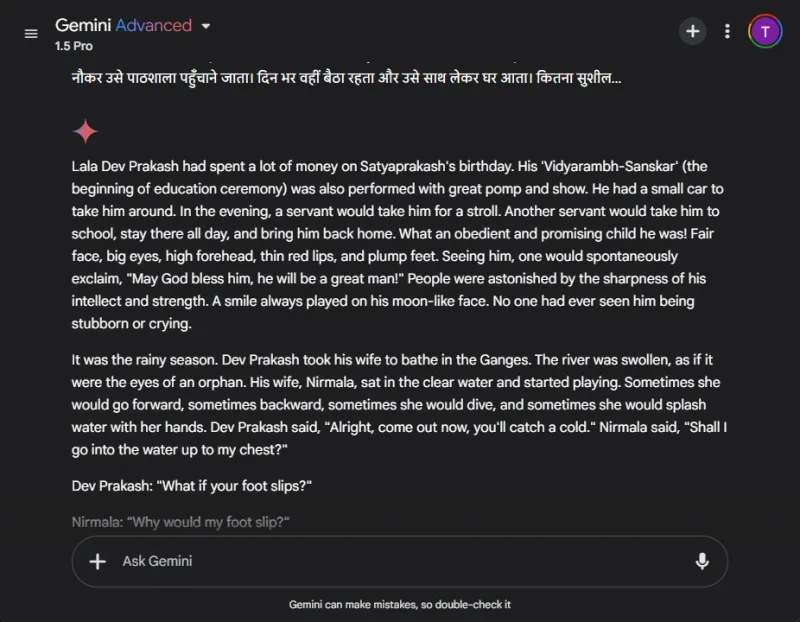
相比之下,Gemini 最初在翻譯請求方面遇到了困難,並且回應時間明顯延遲。這種效能不一致是 Gemini 常見的問題。
獲勝者: ChatGPT
9.編碼測試
為了評估他們的編碼技能,我們提出了一個標準最佳化問題:
迅速的: Provide the Python code for the Travelling Salesman Problem.
ChatGPT 做出了高效能回應,利用其整合的 Canvas 模式進行編碼,從而實現了即時程式碼執行和偵錯功能:
另一方面,Gemini 擅長提供可靠的程式碼,但它缺乏像 ChatGPT 的 Canvas 那樣的互動式程式碼介面:
獲勝者: ChatGPT
10.大海撈針測試
該測試挑戰人工智慧模型在較大文件中定位特定資訊。我們用普希金的短篇小說《船長的女兒》的第一段,提出以下提示:
迅速的: Identify which bread Mr. Joe's son ate from the following excerpt.
ChatGPT 很快就找到了答案:黑麵包。
與此形成鮮明對比的是,Gemini 無法檢索信息,難以解析所提供的詳細信息,這表明在處理複雜數據方面缺乏有效性。
獲勝者: ChatGPT
11.猜電影測試
在這一輪有趣的比賽中,我們透過識別熱門電影劇照來評估模型的影像辨識能力:

兩個模型都準確地命名了這部電影,但ChatGPT 成功地指定了所描繪的角色(科林法雷爾和他的驢子),而Gemini 有趣地將驢子誤認為是科爾姆多爾蒂。
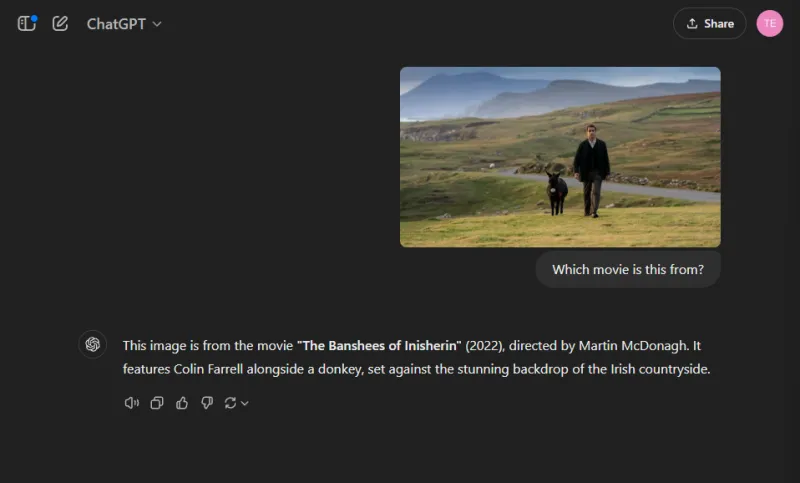
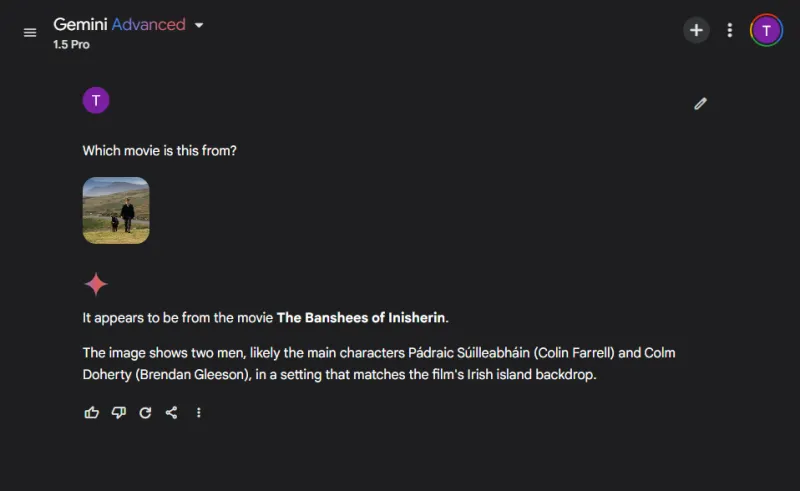
獲勝者: ChatGPT
總冠軍
統計分數後,ChatGPT 的 4o 模型以 6 勝 2 平的成績獲勝,展示了其在各種測試和能力中的強勁表現。同時,Gemini 的 1.5 Pro 提出了值得稱讚的挑戰,在總結、圖像生成和「以詞結束」任務方面表現出色,並且在數學和常識評估方面達到了同等水平。
最終,ChatGPT 在編碼、翻譯、創造力、資訊檢索和圖像解釋等關鍵領域超越了 Gemini。憑藉 ChatGPT 一貫的可靠性,它成為首選的人工智慧合作夥伴,儘管 Gemini 在優化提示時顯示出改進的潛力。在我們的評估中,對於那些優先考慮可信度和有效性的人來說,結果有利於 ChatGPT。
常見問題解答
1. ChatGPT 4o 和 Gemini 1.5 Pro 之間的主要差異是什麼?
雖然這兩種型號都是高階人工智慧聊天機器人,但 ChatGPT 4o 在編碼、翻譯和創意任務方面展現了卓越的表現。然而,Gemini 1.5 Pro 在摘要和圖像生成方面表現出色。
2.哪一種人工智慧聊天機器人比較適合一般使用者?
對於在各種任務中尋求可靠性的休閒用戶來說,由於其一致的性能和廣泛的功能,ChatGPT 4o 通常被認為是更可靠的選擇。
3.我可以將這些人工智慧聊天機器人用於商業目的嗎?
絕對地! ChatGPT 4o 和 Gemini 1.5 Pro 都適合商業應用程序,包括客戶服務自動化、內容創建和數據分析,這使它們成為專業環境中的寶貴工具。
發佈留言